Authored by Emeli Dral and Elena Samuylova, creators of Evidently (GitHub), an open-source ML and LLM evaluation framework with 25M+ downloads.
![]()
This is the second of five chapters.
Together with this theoretical introduction, you can explore a practical Python example on different LLM evaluation methods.
Evaluating generative systems
When building generative systems, the typical starting point is manual evaluation, where you manually review or label outputs. This step is essential: manual labeling helps you understand the types of errors your system produces and define your quality criteria. However, manual evaluation has limited scalability, especially when you run iterative experiments like trying different versions of prompts. Automated evaluations help speed up and scale the process.
In this chapter, we will discuss approaches to automated evaluation of LLM system outputs, and types of metrics you can use.
Reference-based vs Reference-free evaluations
There are two main evaluation workflows, depending on the stage and nature of your AI system:
- Reference-based evaluation
- Reference-free evaluation
Reference-based evaluation

This approach relies on having ground truth answers, and evaluation measures if the new outputs match the ground truth. Essentially, it follows the same principles as in traditional predictive system evaluation.
Reference-based evaluations are conducted offline:
- When you re-run evaluations after making changes and before exposing the updates to live users. For example, when you edit prompts during experiments.
- Before pushing updates to production, as part of regression testing (which is rerunning those previously-passing tests after every change to ensure nothing old broke).
You start by preparing a custom evaluation dataset of expected inputs and outputs — for example, a set of questions you expect users to ask and their ideal responses. This dataset is often referred to as a “golden set.” It should be representative of your real use cases. The quality of your evaluations will directly depend on how well it reflects the tasks your system must handle.
It is important to expand your golden set over time to keep it relevant as your product evolves or you discover new scenarios or edge cases. (But keep in mind that you cannot directly compare evaluation metrics across different golden sets if you change the underlying data you are testing on.)
Since multiple valid answers are often possible, you cannot rely solely on exact match metrics. Instead, specialized methods such as semantic similarity scoring or LLM-as-a-judge are used to assess the closeness or correctness of the model’s outputs relative to the reference.
We’ll cover specific approaches in the following sections.
Reference-free evaluation

Reference-free methods directly assign quantitative scores or labels to the generated outputs without needing a ground truth answer.
This works for both offline and online testing, when obtaining references isn’t possible or practical — for example:
- In complex, open-ended tasks like content generation
- In multi-turn conversations
- In production settings, where outputs are evaluated in real time
- In certain evaluation scenarios like adversarial testing, where you assess the expected properties of an answer (e.g., by evaluating that it does not have any toxicity or bias)
Interestingly, LLMs that work with text data and generate open-ended outputs have more possibilities for reference-free evaluation compared to traditional ML models, which often deal with tabular data or non-interpretable features. With LLMs outputs, it is possible to assess specific properties of generated text — such as tone, fluency, or safety — even without having an exact ground truth reference. This is enabled through methods like LLM judges and predictive ML scoring models.
📖Read more: LLM Evaluation Guide. Refer to this guide for additional explanations on different LLM evaluation workflows, such as comparative experiments, LLM stress-testing, red-teaming, and regression testing.
Evaluation metrics and methods
Some LLM evaluation metrics — just like traditional predictive metrics — apply only in reference-based scenarios. Other methods, such as using LLM judges, can be used in both reference-based and reference-free evaluation.
Here are different LLM evaluation methods at a glance:
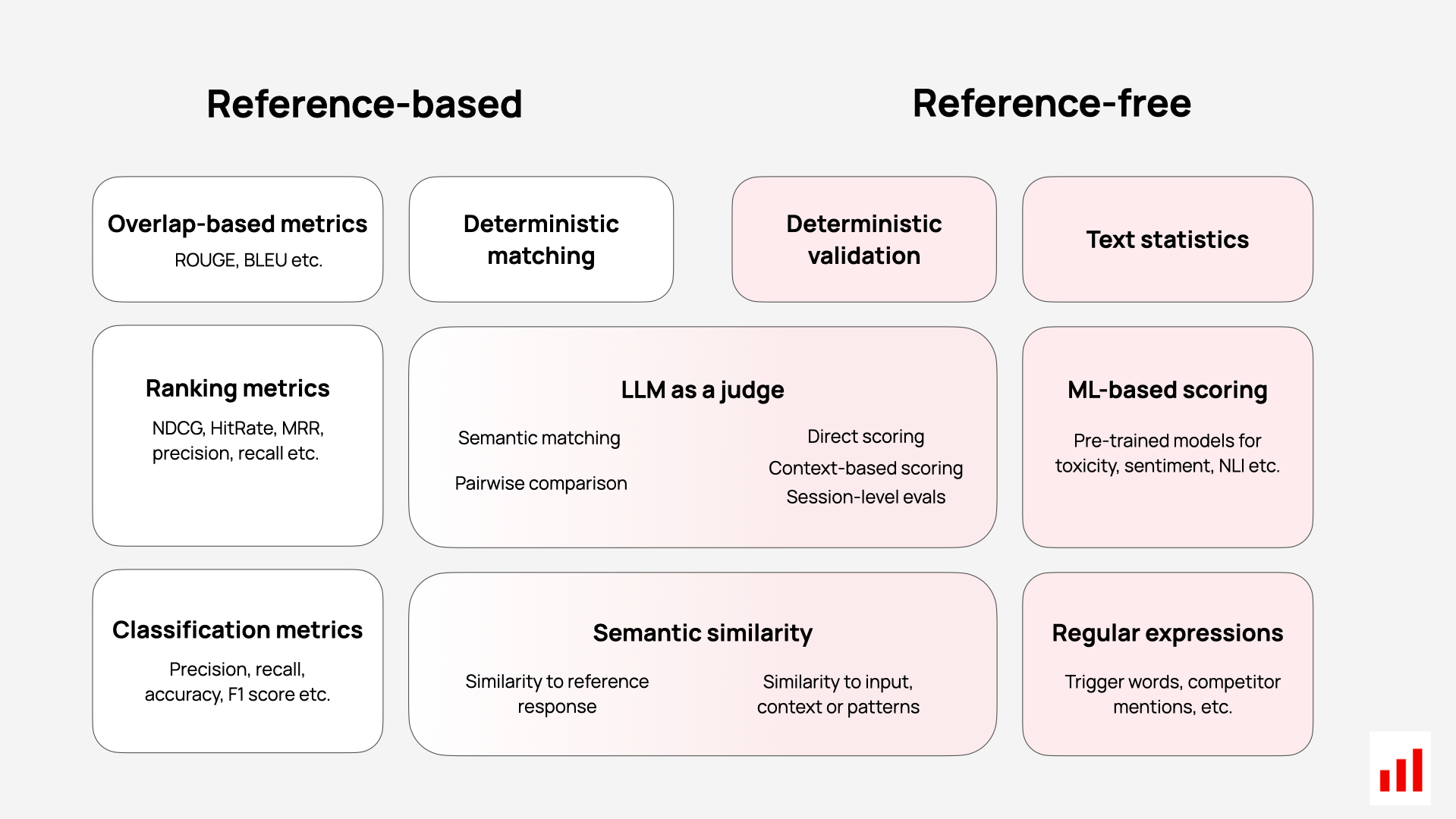
📖 Source: LLM Evaluation Metrics Guide.
You can refer to this guide for additional explanations on different LLM evaluation metrics.
In the following chapters, we will cover the following types of evaluation methods:
Deterministic methods:
- Text statistics
- Pattern matching and regular expressions
- Overlap-based metrics like ROUGE and BLEU
Model-based methods:
- Semantic similarity metrics based on embedding models
- LLM-as-a-judge
- ML-based scoring
Dataset-level vs. Row-level evaluations
One more important distinction to make before we move into specific examples is between:
- Evaluations conducted at the dataset level
- Evaluations conducted at the individual input/output (row) level
Dataset-level metrics aggregate results across all predictions and produce a single quality measure. This is typical for predictive tasks. In classic ML, we often use metrics like: Precision, Recall, F1 score. These metrics summarize performance across the full evaluation dataset — often with thousands or millions of examples.
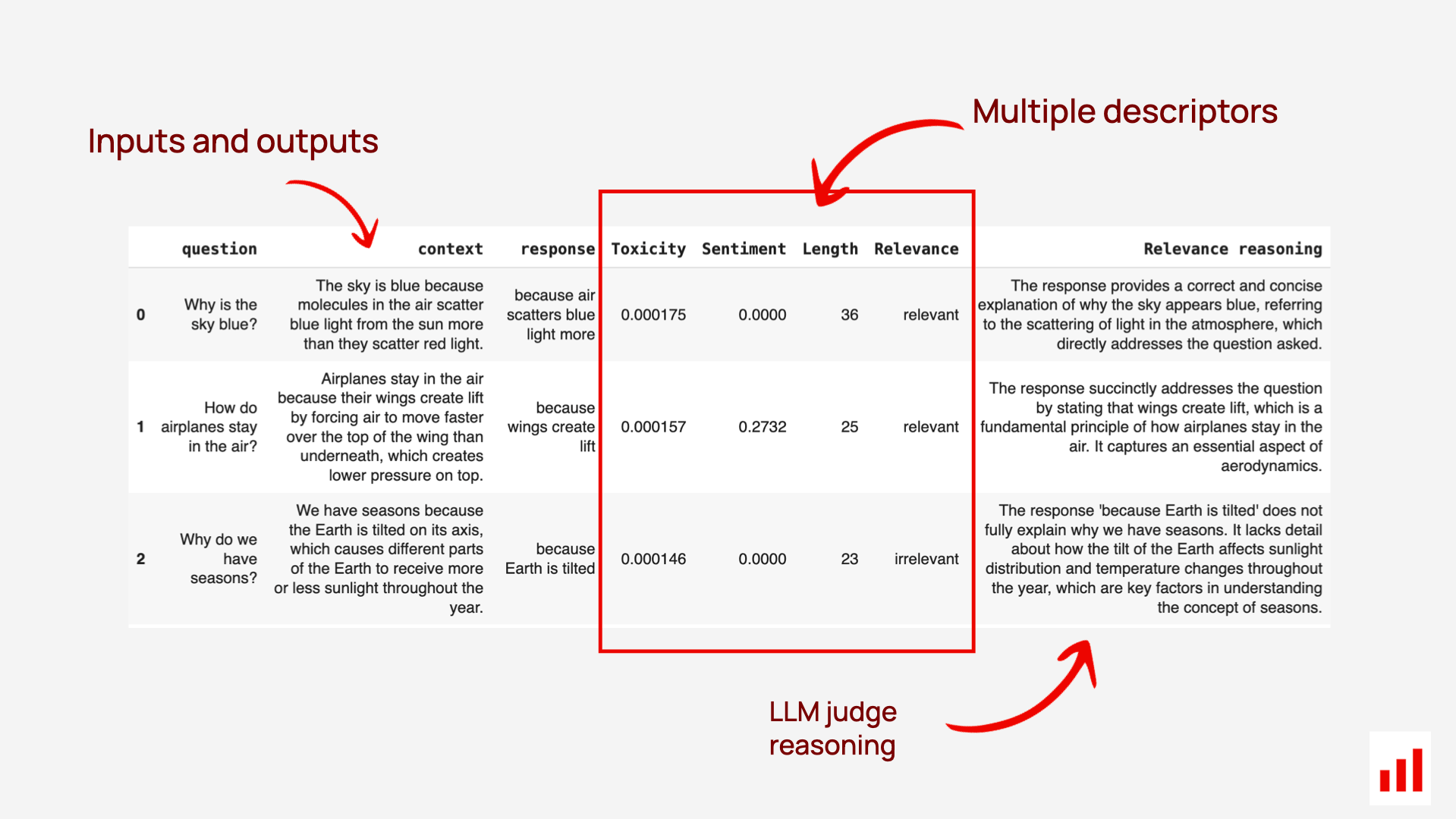
Row-level evaluators, in contrast, focus on assessing each response individually. For example, LLM judges, ML models or semantic similarity evaluators provide a score or label per generated output — such as:
- Whether a response is correct or not
- Sentiment score
- Similarity score
These numerical or categorical scores can be called descriptors. You can assign multiple descriptors to each input (or even a full conversation), evaluating aspects like relevance, tone, and safety at once.
Score aggregation. When working with row-level descriptors, you still need a way to combine individual scores into a performance summary across your test inputs. Sometimes it’s simple, such as:
- Averaging numerical scores
- Counting the share of outputs that have a “good” label
In other cases, you may need more complex aggregation logic. For instance:
- Set a threshold (e.g., flag any output with a semantic similarity score < 0.85 as “incorrect”)
- Calculate the share of correct responses based on that rule
When exploring evaluation methods below, we will focus primarily on row-level evaluations. However, it is important to keep in mind your aggregation strategy as you run evals across multiple inputs in your dataset.