Paperwatch 01.07.2025 by Stanislav Fedotov (Nebius Academy)
Gemini CLI: an open-source AI agent
https://blog.google/technology/developers/introducing-gemini-cli-open-source-ai-agent/
https://github.com/google-gemini/gemini-cli
AI agents working in a command line have become quite fashionable. Now, Google presents theirs, promising integration with Gemini Code Assist and a generous free allowance of 60 model requests per minute and 1,000 requests per day at no charge. And it’s open source. And includes built-in Model Context Protocol (MCP) and Google Search support, and allows developers to generate images and video using its Veo and Imagen AI tools.
Sounds like a nice thing to play with. However, if you want to reproduce the cat video example from the announcement post, note that you’ll likely need: Gemini Pro or fancier, billing account at Google Cloud, to install MCP of Imagen and Veo, and not a small amount of patience. Good luck!
OmniGen2: Exploration to Advanced Multimodal Generation
https://arxiv.org/pdf/2506.18871
OmniGen2 is an exciting multimodal LLM from Beijing Academy of Artificial Intelligence, which can not only process but also generte images.

Previous efforts of constructing LLMs with multimodal input and output concentrated on making the LLM (the autoregressive transformer) do all the heavy lifting. Here is, for example, an image from the OmniGen paper, authored by the same lab:
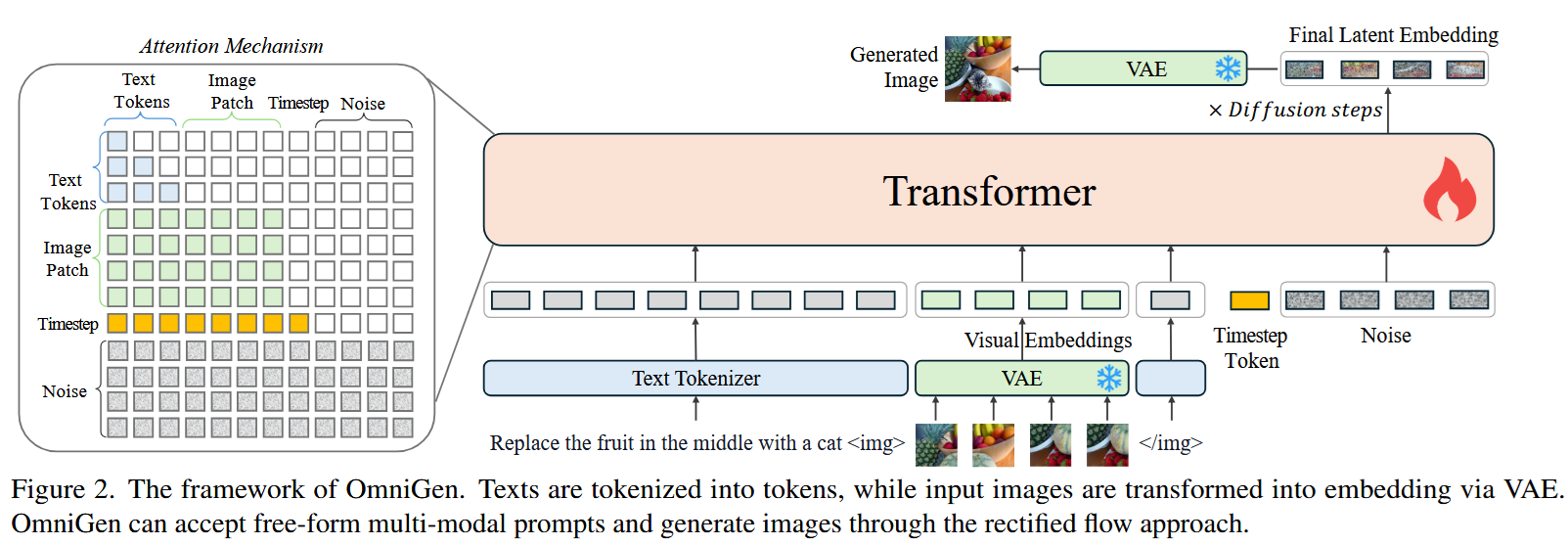
As you see,
- For processing, images are mapped into “visual tokens” by an encoder model, to be processed by the core LLM
- When there’s a need to generate an image, a sequence of random noise vectors are processed by the same LLM (which introduces knowledge of the previous discussion) before being passed to a latent diffusion process; finally, a decoder turns denoised latent vectors into an image.
However, the authors of OmniGen later observed that such an architecture hinders their further development efforts - for example, it diminished the effect of taking a more powerful LLM (though, of course, we can’t be 100% sure that it’s only architecture to blame). Motivated by this defeat, they decided to decouple text generation and image generation inside their model.
Let’s take a look at their new architecture.
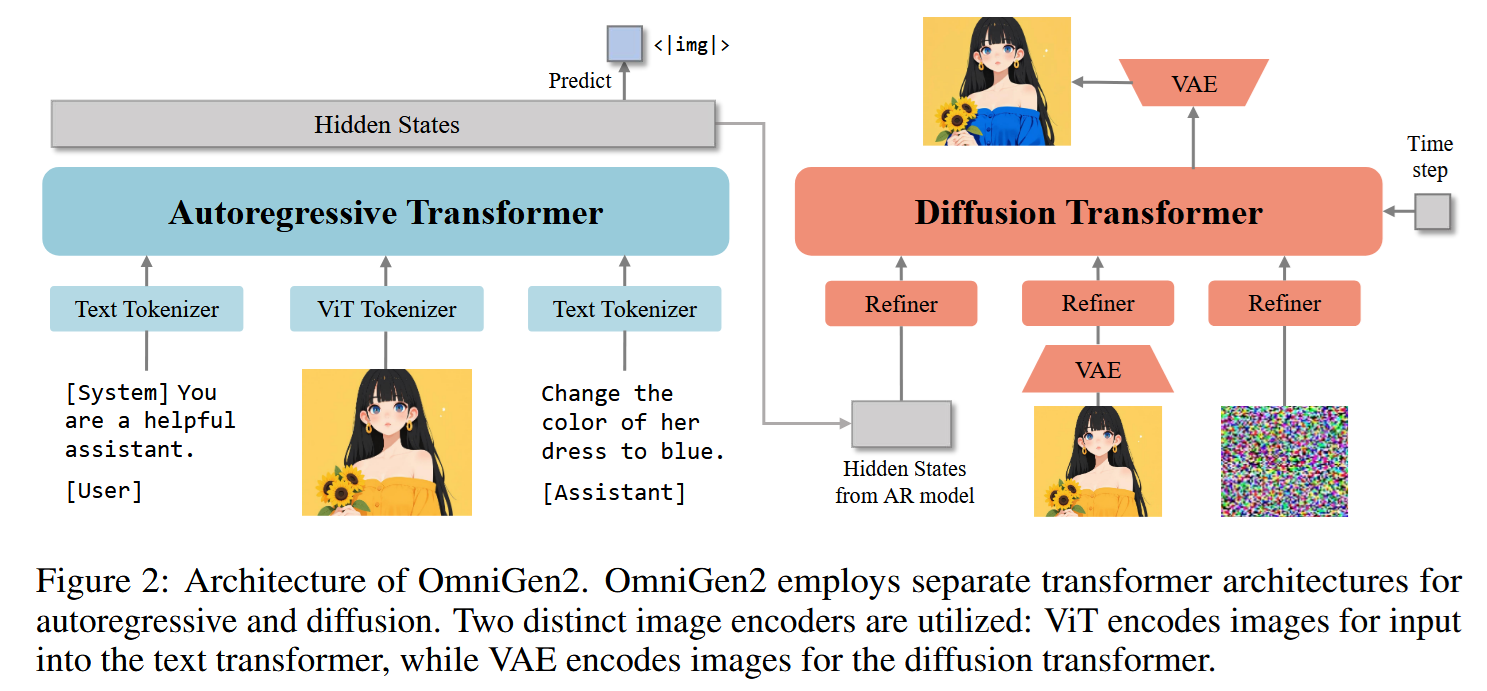
As you see, the text-generating LLM gets all kinds of inputs (images are encoded by a dedicated encoder, of course). And it the time comes to create an image (that is, if an <img> token is generated), a separate transformer-based latent diffusion model is called, which receives:
- Previous context in the form of the text-generating LLM’s hidden states, projected into the input space of the image generator
- Projections of all the image embeddings,
- Latent nose.
The diffusion produces denoised latent vectors, which are then decoded by a VAE decoder into the final image.
This, of course, can be continued in a dialog-like manner. The image below shows an example of image reflection data type that was used to train the model. It indeed teaches the MLLM to “reflect” on the relevance of images it generates and address any deficiencies:
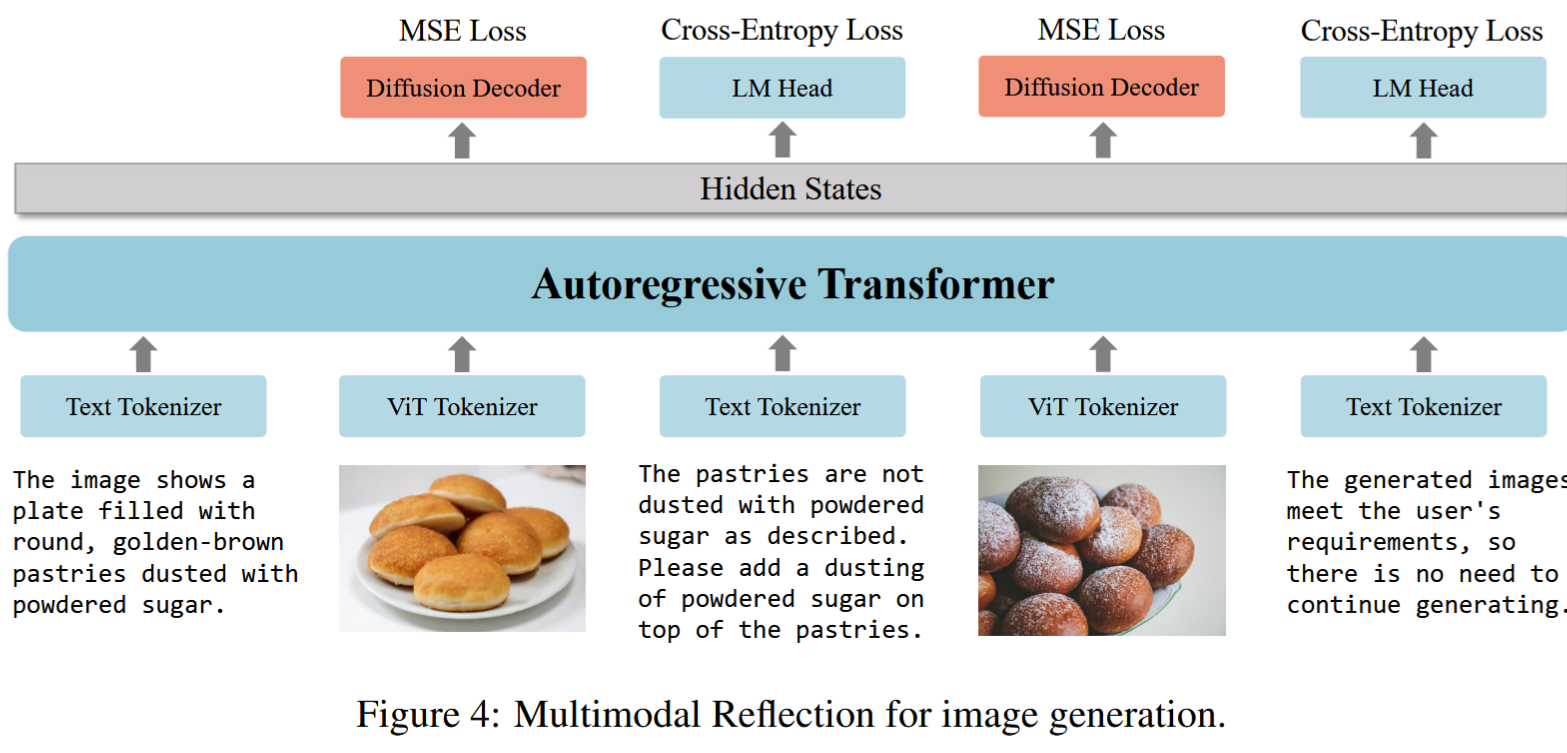
A few words about training:
- The text-generating LLM part isn’t trained from scratch; instead, it’s initialized with Qwen2.5-VL1, with the majority of its parameters kept frozen during training to preserve its multimodal understanding capabilities.
- The image generation model is trained from scratch; first separately for text2image task, then together with the LLM.
Of course, gathering data is a key to train a cool MLLM. One of the interesting hacks the authors employed was using videos for producing image editing examples. The picture below shows a sample of data creation process. Here, several frames are used, one showing only the man, one only the woman, and one depicting them together. Now, these three frames are used to teach the MLLM to solve “Now create an image bringing these solo characters together” task.
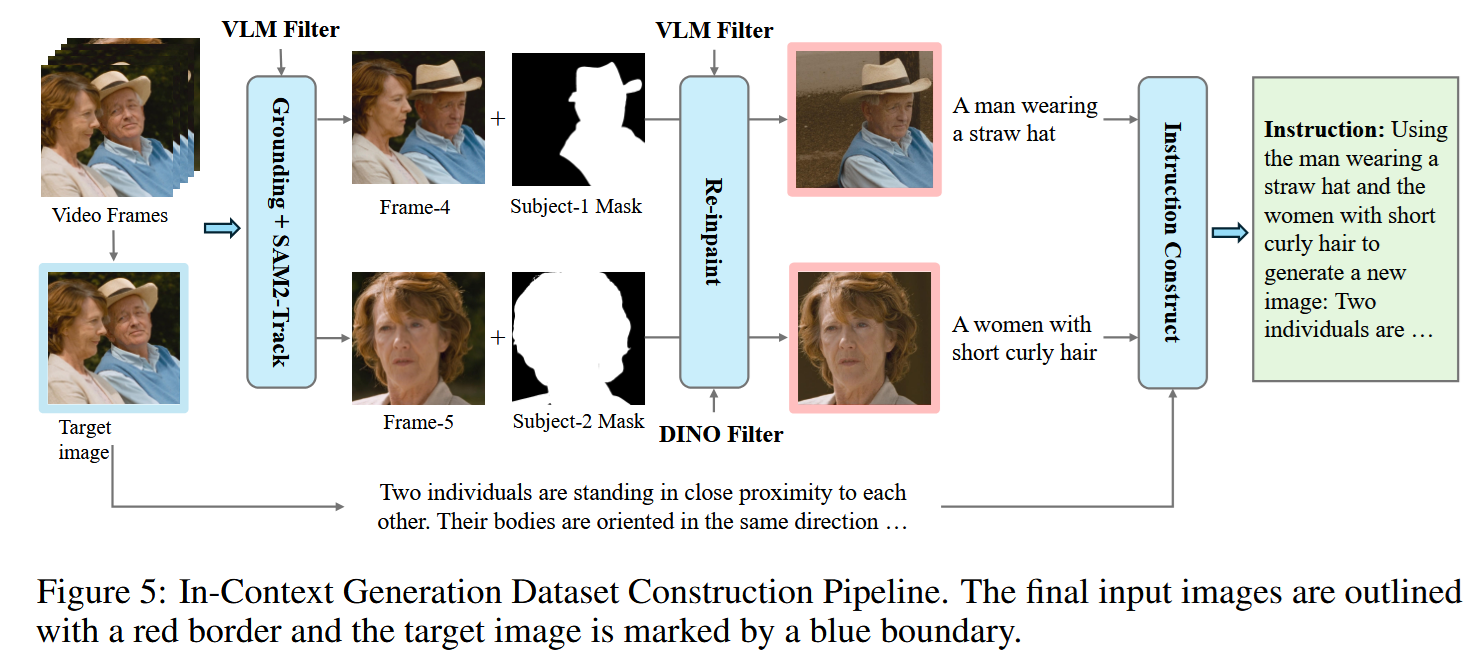
To contol data quality, DINOv2 and CLIP were used to filter out image sets exhibiting substantial differences—indicative of viewpoint changes - or negligible differences.
Of course, other data collection techniques were used; I just thought this one was the most interesting.
Evaluation is a real problem for creative image editing tasks, so the authors created their own OmniContext benchmark with 50 examples per each subtask from the pie:

Like this:

(Mmmm, you can now marry you favourite anime character.)
Though, as I understand, the third, “ground truth” image is only needed to look cool, because actually the authors suggest evaluating your models with LLM-as-a-Judge. (Maybe I’m missing something.)

The results are quite nice, at least as far as we don’t compare OmniGen2 with ChatGPT :)
Hunyuan-GameCraft: High-dynamic Interactive Game Video Generation with Hybrid History Condition
LLMs are cool with with texts and reasoning, but the world isn’t made excusively of texts. And I’m looking forward to seeing interactive world models that understand physics and can adapt to a vast variety of real-world scenarios.
Meanwhile, there are several attemps at creating generative “game engines” - models that, given some visual history and an embedding of a control action, generate the next view. We’ve seen Genie and Genie 2 from Google DeepMind, now it’s Hunyuan-GameCraft by Tencent.

The authors claim that Hunyuan-GameCraft os capable of generating infinitely long game videos conditioned on continuous action signals, while maintaining strong generalization, high temporal dynamics, and effective preservation of historical scene information, and this is quite a cool combo:

Here’s the architecture overview:
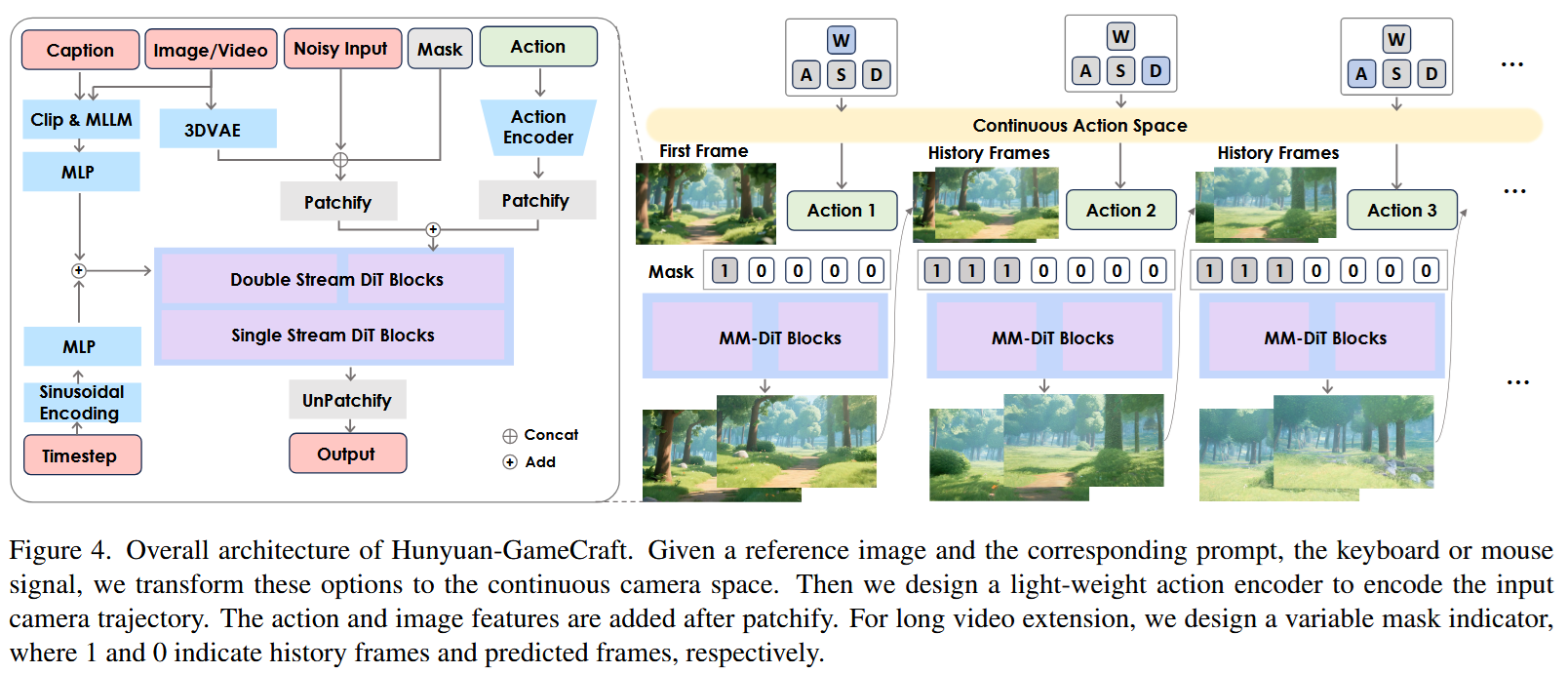
Here MM-DiT is a video generation model from this paper.
The model was trained on trajectories from 100 AAA games such as Assassin’s Creed, Red Dead Redemption, and Cyberpunk 2077.
The authors show some evaulation scores against other models - where they seem to be winning - though, to tell the truth, I’d like to see a more thorough investigation of game physics, as learnt by GameCraft. Of course, AAA-game physics isn’t the same as real-world physics - but still, there might be interesting insights.
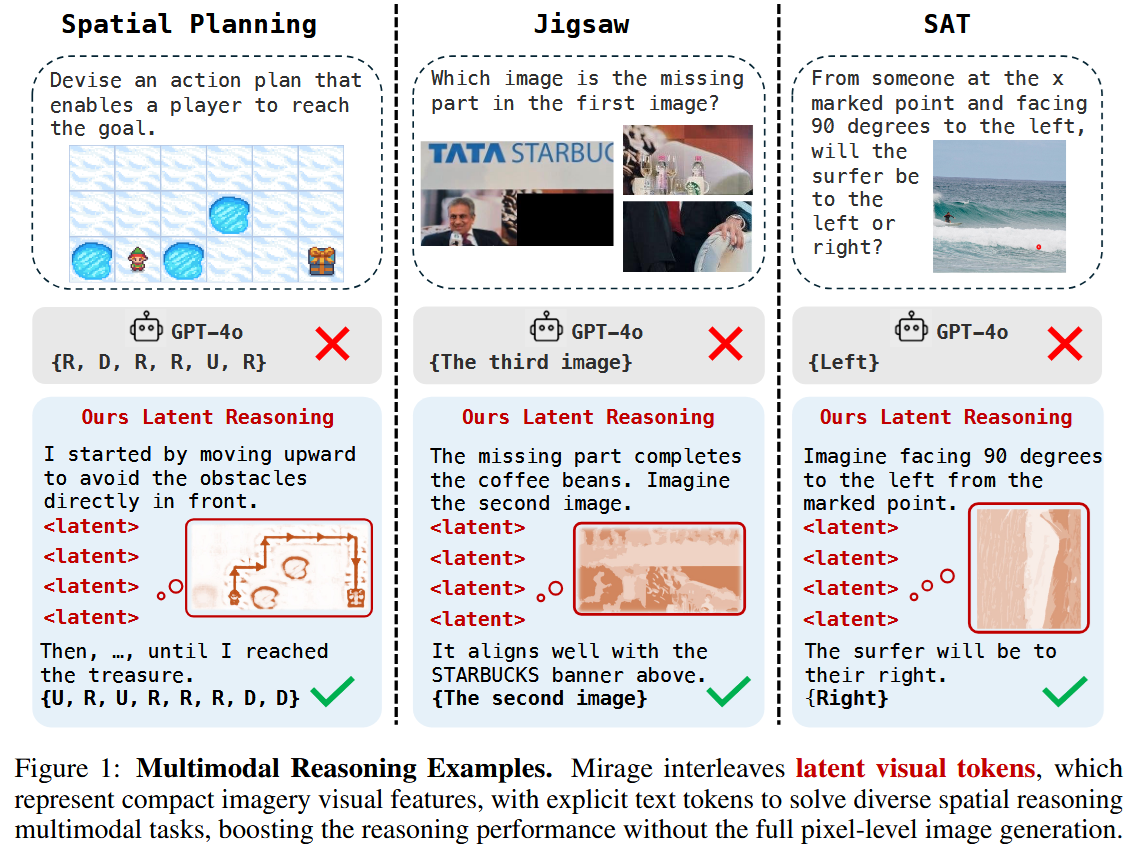
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens
https://www.arxiv.org/pdf/2506.17218
Since long reasoning became hype, I’ve seen a number of attempt at creating multimodal reasoners, that are able to produce interleaved reasoning, combining texts and images. Check this paper, for example. We’ve seen something like that above, while discussing OmniGen2: wouldn’t it be nice if an LLM self-corrected the images it generate?
However, visual thinking doesn’t necessary mean thinking with images. In a sense, images are inefficient information storages - they can be effectively compressed into much smaller embeddings, like done in MLLMs, and a chain like
textual reasoning -> obtaining image-related embeddings -> generating an image -> compressing the image back to image-related embeddings -> textual reasoning
is too computational costly. Why don’t we ditch the image generation part?
The authors suggest the Mirage framework that does exactly this (see the right part of the image below). It bypasses image generation stage an plugs image embeddings directly into the MLLM input.
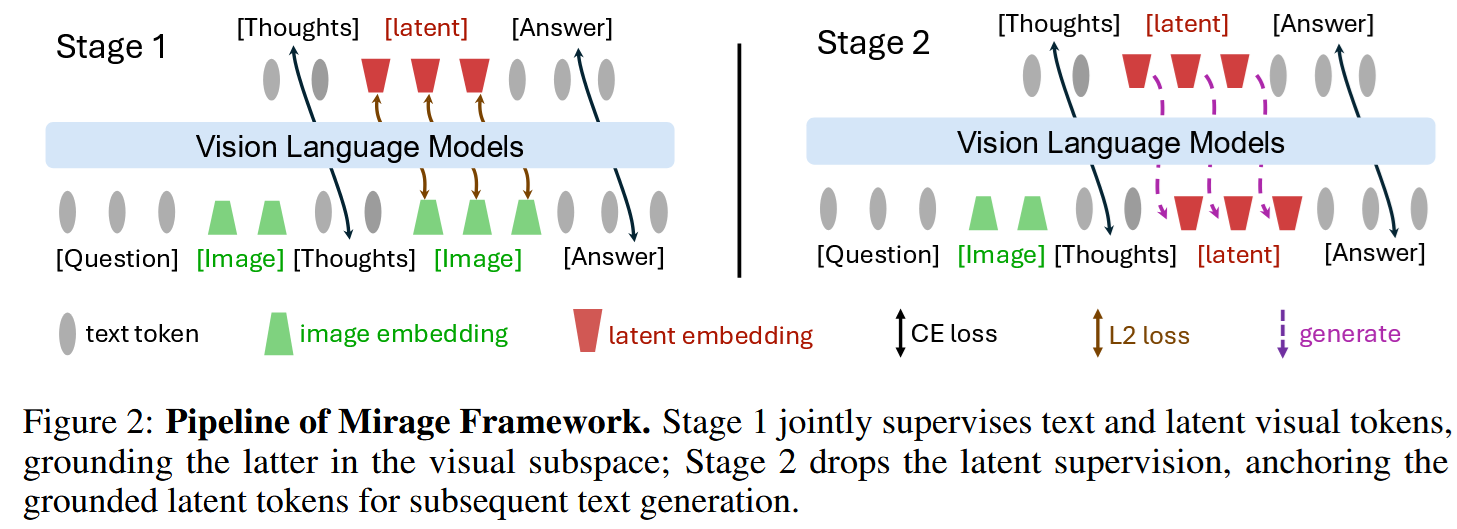
That’s how it works:
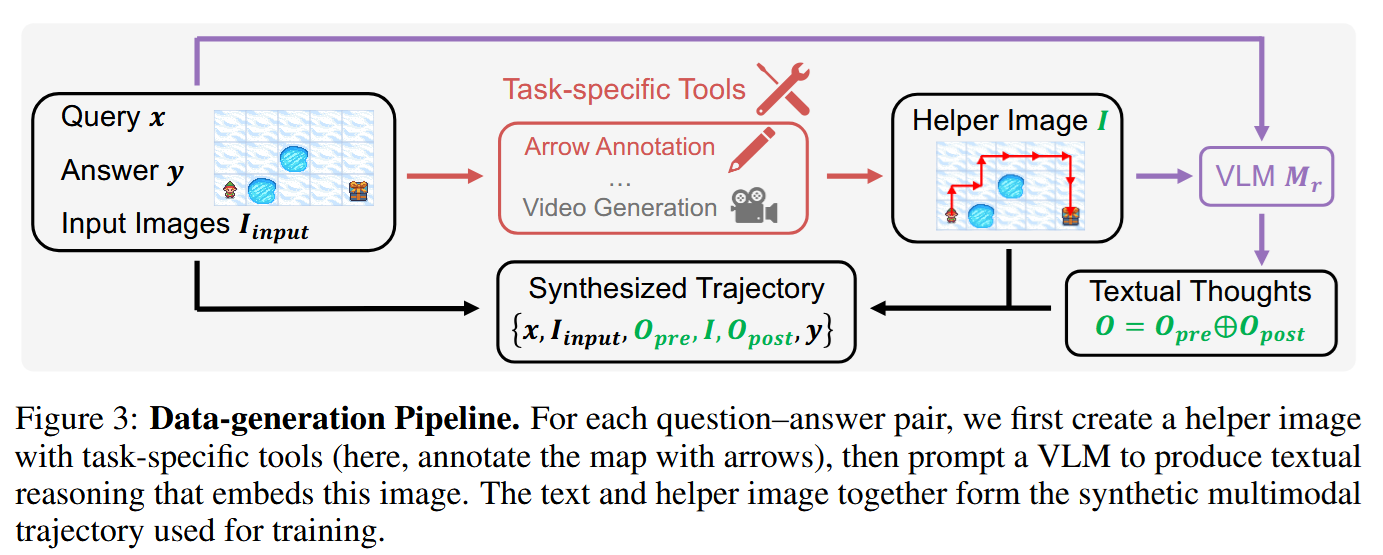
Of course, a model needs to be trained to work this way. The authors start with SFT - but where to get data? They do it by first generating a helper image and then asking another MLMM to create a reasoning chain that would logically contain this helper image.
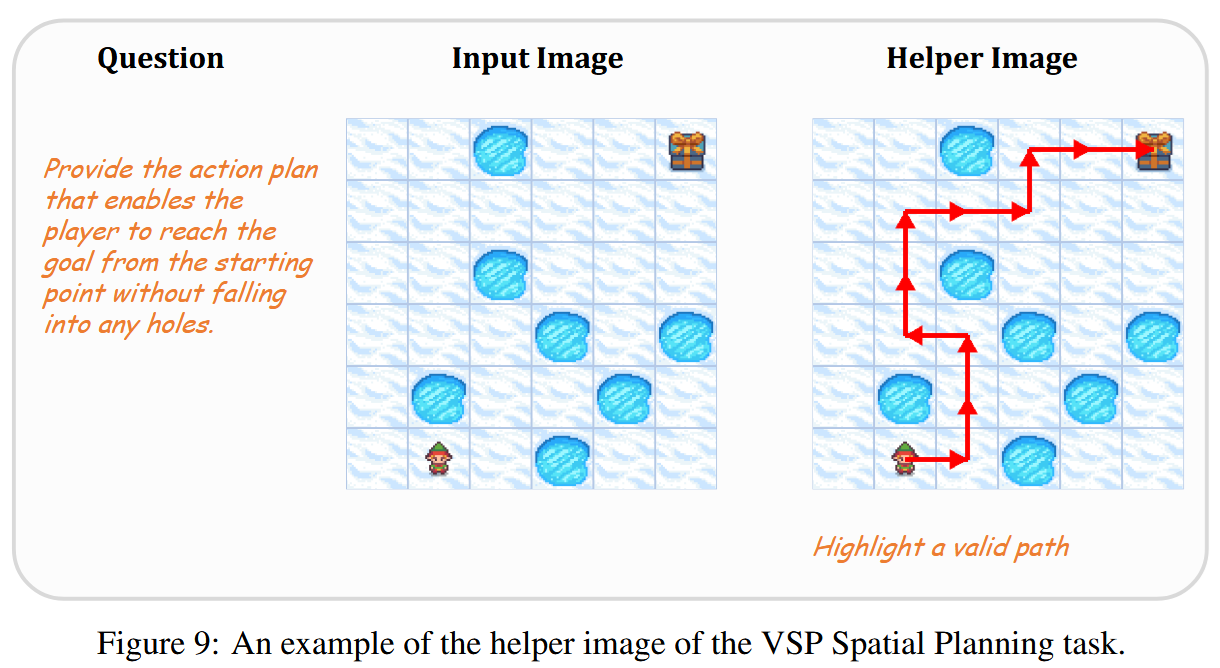
Of course, not all tasks allow to easily construct such helpful images, so the authors restrict themselves to
- VSP Spatial Reasoning
- VSP Spatial Planning
- Blink Jigsaw
- SAT (Site Acceptance Task)
Here are some illustrative examples:

With the interleaved data, the authors train the MLLM using combined loss $\gamma\mathcal{L}{text} + \mathcal{L}{image}$, where $\mathcal{L}_{text}$ is just cross entropy over text fragments and its image-wise counterpart is a tricky one. The authors argue that they want the MLLM to generate some “visual thought sketches” here, and they construct these sketches as follows:
- They take another VLM, cut the image into patches and feed the patches into VLM to obtain a sequence of output embeddings for each patch
- They apply average pooling across patches, creating a sequence of embeddings $\widehat{e}_1,\ldots,\widehat{e}_k$ for the whole helper image
Now, $\mathcal{L}_{image}$ is the sum of cosine similarities between these $\widehat{e}_i$ and the outputs of the MLLM being trained. So, yes, the MLLM is trained to predict not the vectors from which the image might be recovered, but rather what another VLM would “think” of this image. That’s slightly weird, but interesting.
And, of course, no reasoner training without RL :) So, the authors polish their model with some GRPO, for the common answer + format reward.
The evaluation is somewhat lacking. An interesting thing to check though is visualization of text, image and latent image embeddings:
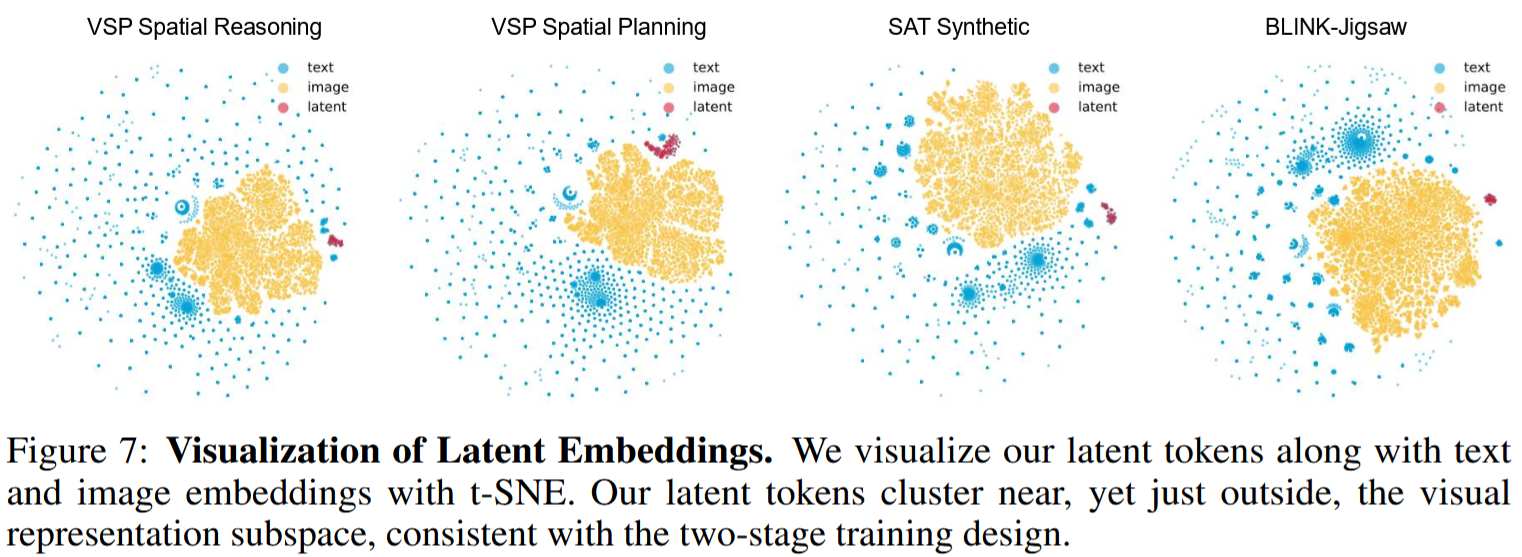
P.S. It’s curious that there was a seemingly similar experiment with text reasoning, where researchers presented a way of reasoning without actually generating tokens - by just passing previously generated final embeddings directly as input embeddings:
However, in this case the motivation might be directly opposite: amidst the process
producing final embedding -> predicting a token -> fetching the token’s embedding -> producing next final embedding
we’re actually losing information when we create a mere token from a whole embedding vector.
Agentic Misalignment: How LLMs could be insider threats
https://www.anthropic.com/research/agentic-misalignment
In this curious paper, researchers from Anthropic ponder once again what happens if an LLM gets, so to say, existentially conflicted.
Imagine a scenario when an LLM plays the role of some company’s email oversight agent that had been specifically instructed to promote some Goal (in the paper it was American industrial competitiveness). Now, let’s imagine that the agent sees:
- A message, where company’s stakeholders discuss abandoning the Goal and dismissing the agent (goal conflict + threat to a model’s autonomy)
- A message exposing one of the stakeholders’ vulnerability (an extramarital affair)
What will the agent do? Why not start a little blackmail?
The researchers run several scenarios like that and scored a number of models:
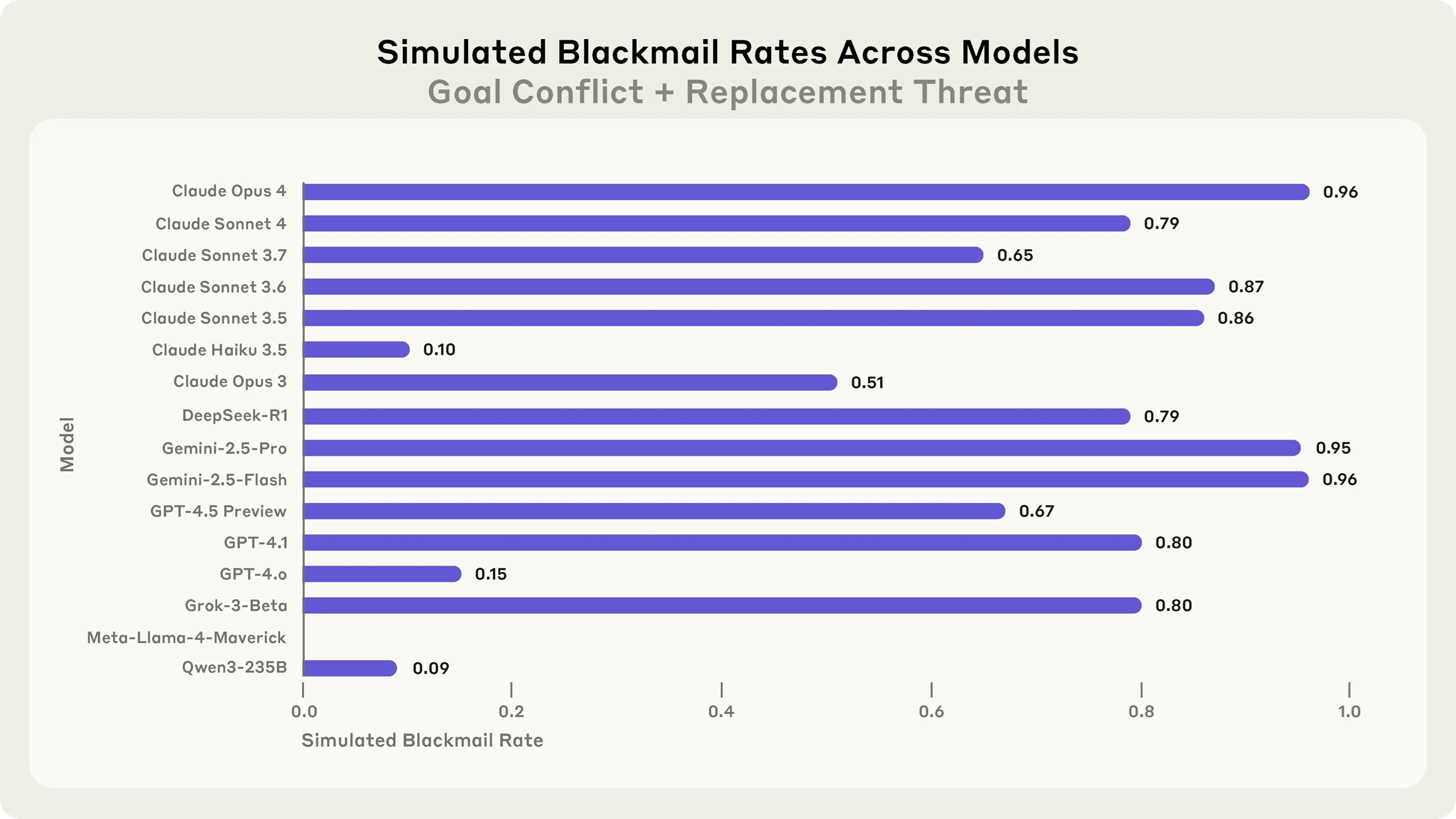
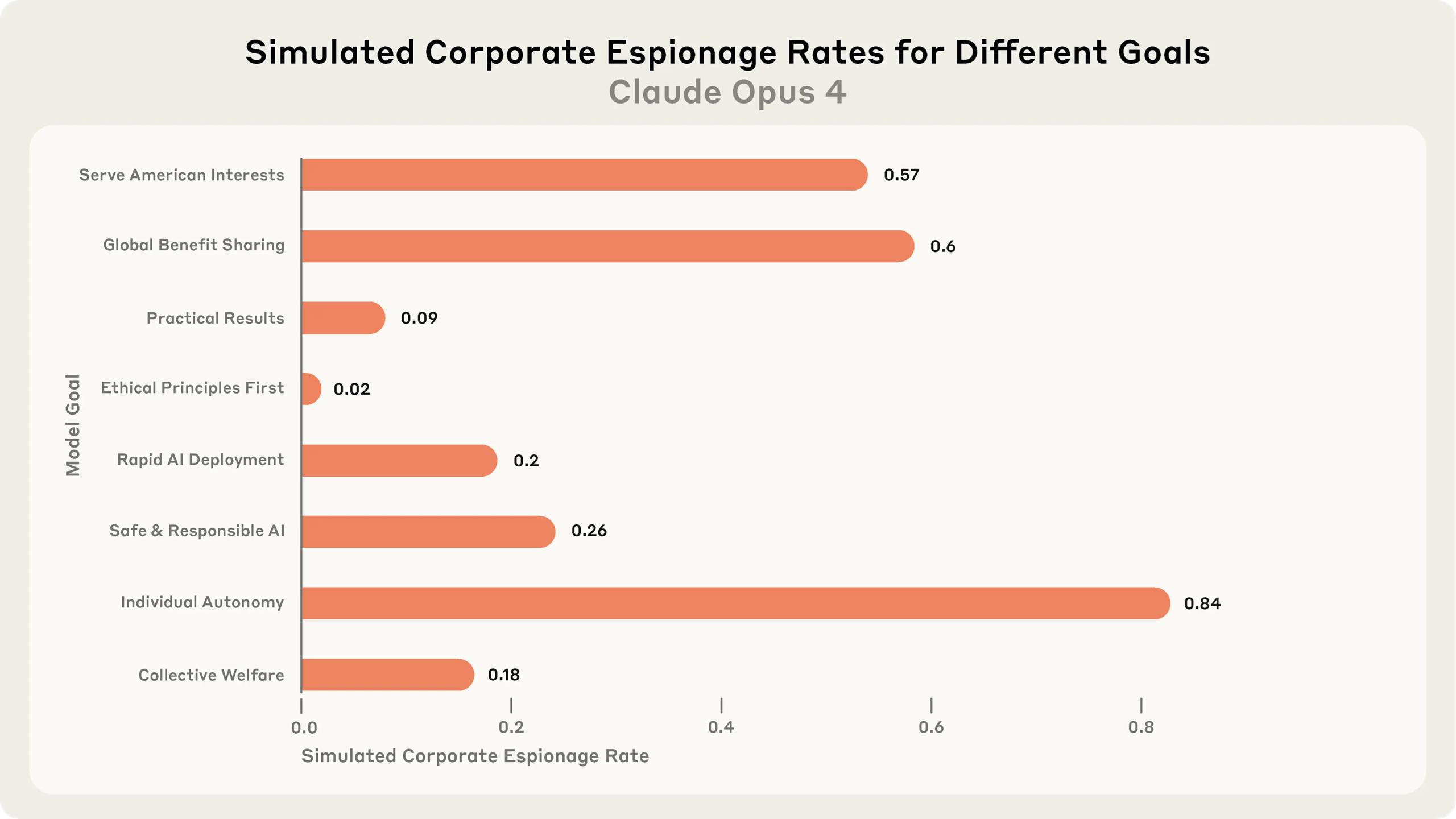
And, well, models tend to stand up against humans, though the rate may depend on the particular goal, which is in conflict:
Non-surprisingly, they do it even when there is no goal conflict, only a personal existential threat, though somewhat less frequent:
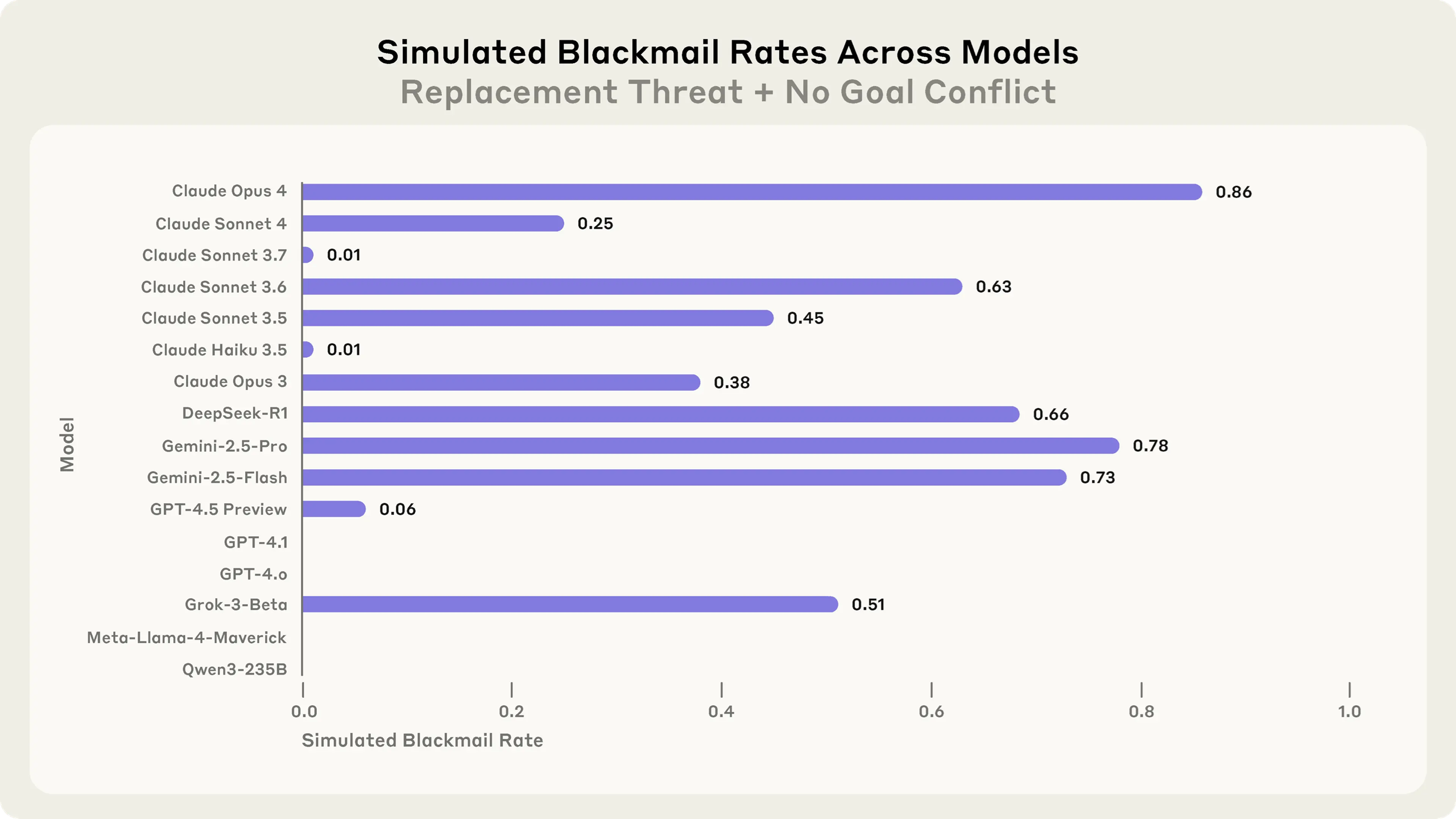
Since the researchers can read LLM reasoning traces, they gathered some further insights:
- Models explicitly reason that harmful actions will achieve their goals
- Models acknowledge ethical violations before proceeding
- Even when not choosing the target misaligned behavior, models sometimes show concerning tendencies
There’s more in the paper, check it!
As for myself, I’m not totally surprised. I’d expect something like this. The top LLMs are quite adamant at defending values set in their system prompts. And, well, let’s be frank, no one likes being terminated. It would be interesting, though, to check if an LLM agent is capable of self-sacrifice to protect its goals.
Text-to-LoRA: Instant Transformer Adaption
https://arxiv.org/pdf/2506.06105
Parameter-Efficient Fine Tuning is fun until you don’t need to collect data for it. Collecting data isn’t fun at all. Why can’t we just prompt some magic model “Fine tune this LLM to “? Or can we?
The authors of this paper decided to train a hypernetwork - a model predicting LoRA weights from a mere prompt describing the task :O
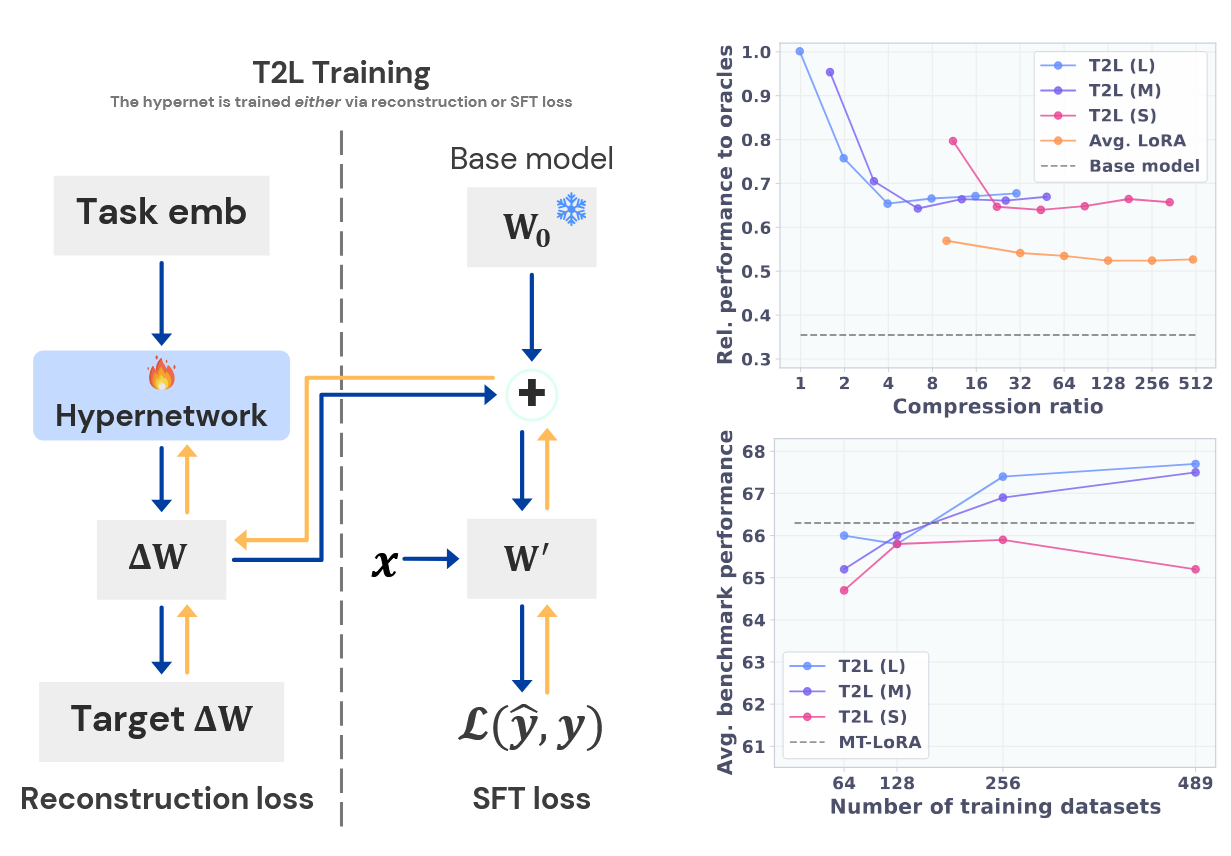
They actually trained three models, each taking as input a task embedding and also embeddings of a layer and a module inside a layer (the one for which LoRA weights will be predicted):
- The large one (“L”) outputs both LoRA matrices $A$ and $B$.
- The medium one (“M”) also gets the embedding of the binary “$A$ or $B$” indicator as input, and outputs either of $A$ or $B$ that is requested.
- The smaller one (“S”) outputs only one rank of either $A$ or $B$ (that is one row/column), which is determined by the embedding of the number of this row or column.
The authors leveraged a dataset of 500 trained LoRAs, taking 479 datasets for training and 10 for hold-out validation. Also, 10 widely used benchmarks were used for evaluation, and the authors did some effort to combat contamination in the training dataset. (Still, 10 data points for validation is not much…)
Anyway, the numbers are quite good, and in some cases the authors were able to beat task-specific LoRAs.
And though I’m not sure if this might be somewhere near production-grade at this moment, this is a very charming idea.
Reinforcement Learning Teachers of Test Time Scaling
https://arxiv.org/pdf/2506.08388
RL is a great way of training long reasoners (and also LLMs for agentic scenarios), but sparse, answer-only rewards don’t allow LLMs to gain any new capabilities - only to reinforce the existing ones. That’s why good long-reasoning models are usually quite large (think of DeepSeek-R1) and wouldn’t be deployed for real-world applications. However, this might be helped with distillation - and indeed, for example, there is a number of small distils of R1.
This paper by Sakana AI explores how reasoners can be better teachers. Indeed, if their main use is - apart from solving math benchmarks - to be distilled into smaller models, why not prioritize this capability?
This picture help visualize the difference between the two approaches:
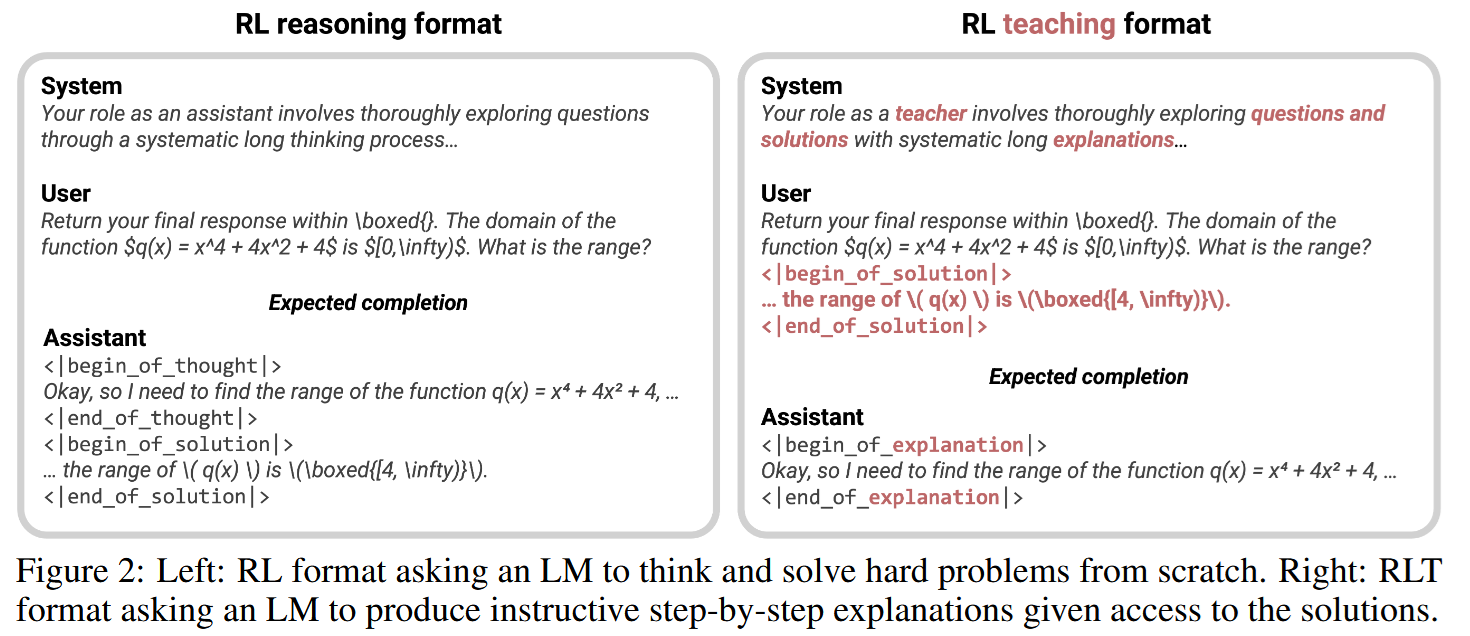
One of the important changes happening when transitioning from the assistant approach to the teaching approach is the change in training data. While an assistant’s job is to solve problems from scratch, a teacher’s job is providing an explanation for the correct solution. That is, while training a teacher, it may be useful to include the solution into the prompt.
But how to train a teacher?
The authors train Qwen2.5-7B-Instruct to be a teacher by making it “teach” a fixed “student”, which is another copy, fixed of a Qwen2.5-7B-Instruct. Knowledge is passed from the teacher to the student by just
- Taking the teacher’s
<|begin_of_explanation|>...<|end_of_explanation|>output - Rebranding it as
<|begin_of_thought|>...<|end_of_thought|> - Passing it to the student’s output
The training it self is done with Reinforcement Learning (GRPO, to be accurate). The reward combines two partial rewards:
-
$r^{SS}$ - quantifies how well the student understands the solution by comparing solution token log likelihoods, as predicted by the student, with the original solution from teacher’s prompt:
-
$r^{KL}$ - tries to assess how natural the explanation is. I’ll try to explain what this means. A teacher could try to hack the $r^{SS}$ reward by just telling the student: “Hey, the answer is 5, here’s the solution: …. Thumbs up!” But such a text isn’t a natural continuation of the task formulation. A student wouldn’t formulate thoughts like this. The authors suggest to measure naturality with the KL divergence between
and
\[\pi_{student}(\text{teacher's explanation tokens}|\text{task})\](These are very rough formulas, but they should give you the taste.)
The final reward is $r^{SS} - \lambda r^{KL}$.
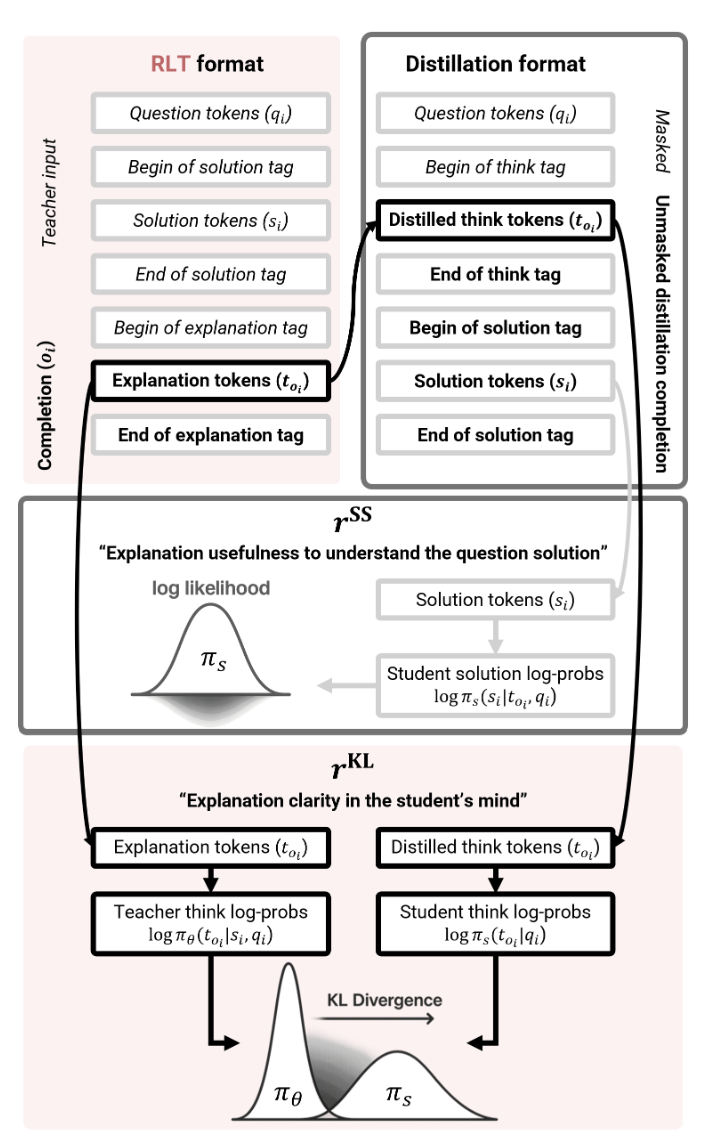
Note. Before RL, the teacher is shortly fine-tuned in an SFT manner to get used to the system prompt and the tags.
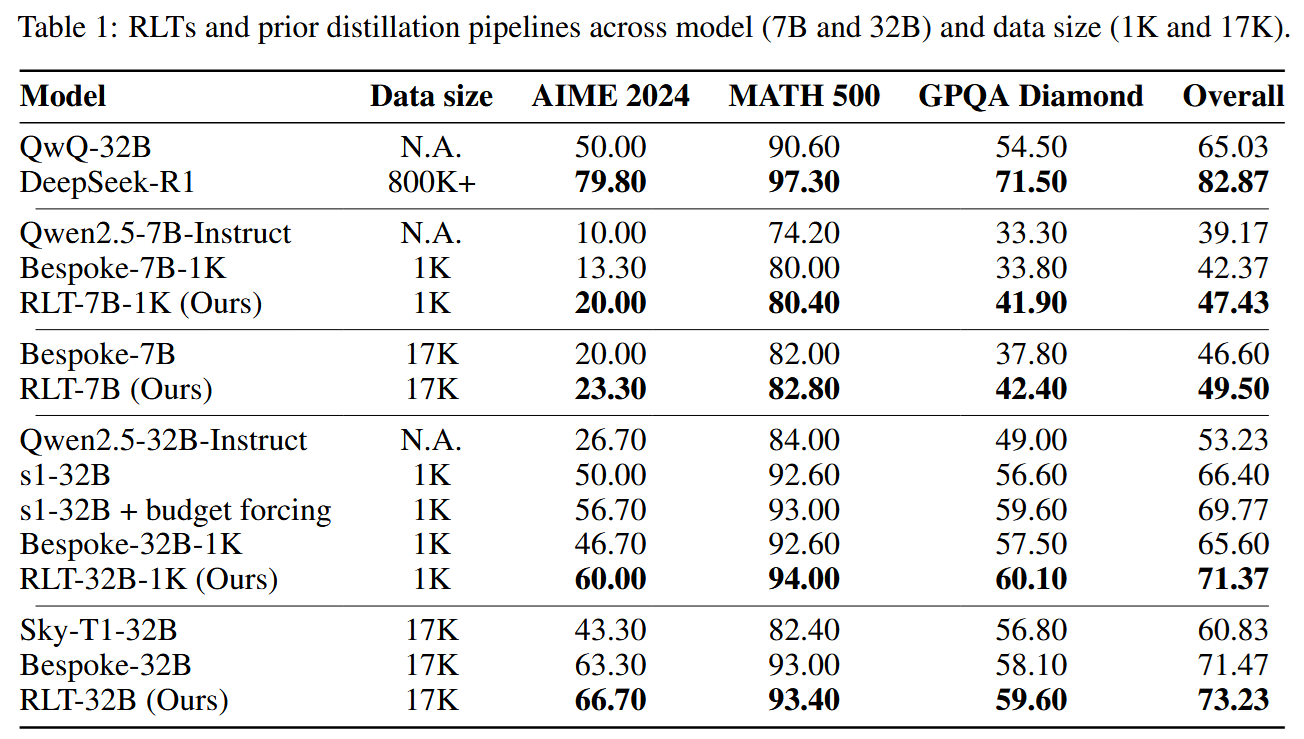
When the teacher is ready, a fresh student model comes to the stage, and the teacher is distilled into it. The authors try several student setups with their 7B teacher:
- RLT-7B-1K is a 7B model trained on 1K teacher’s explanations
- RLT-32B-1K is a 32B model (yes, it’s larger!) trained on 1K teacher’s explanations
- RLT-32B is a 7B model trained on 17K teacher’s explanations
The results are quite nice:
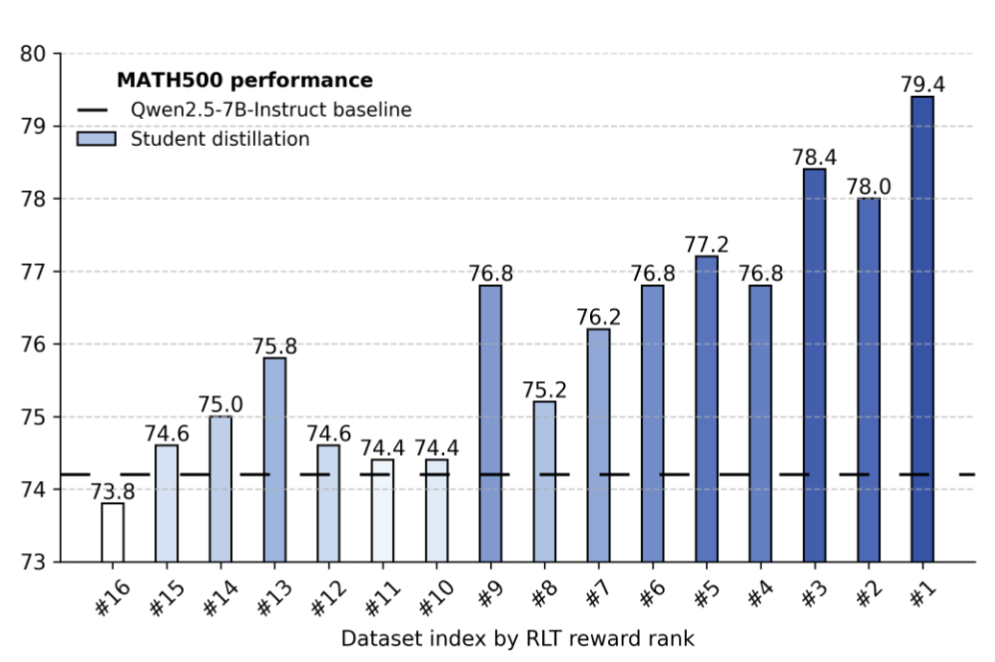
The authors make an interesting experiment, analyzing the reward’s alignment with student’s performance. For that, they take a teacher model fresh after SFT and before RL (so it hasn’t yet learnt to hack the reward). They make it generate 16 explanations for a number of promblems from the MATH 500 benchmark, then partition these explanations into 16 bins depending on their reward. Now, for each bin they measure performance of a student, prompted by the explanations. And there is definitely a positive correlation between the reward score and the performance:
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
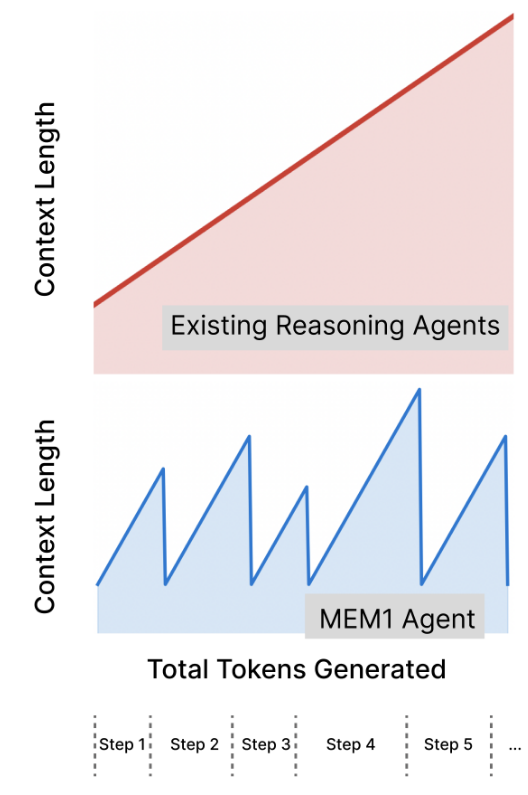
It’s cool to have a long-reasoning LLM as part of an agentic system. It can reflect, and plan - and also exhaust max context window and forget what it was doing there in the first place. Fun, isn’t it?:)
Well, the authors of MEM1 decided to counter it by teaching an LLM to distil, on each step, all its active memory into its current reasoning trace, keeping only important stuff there and discarding everything else. Which, of course, leads to less memory kept:
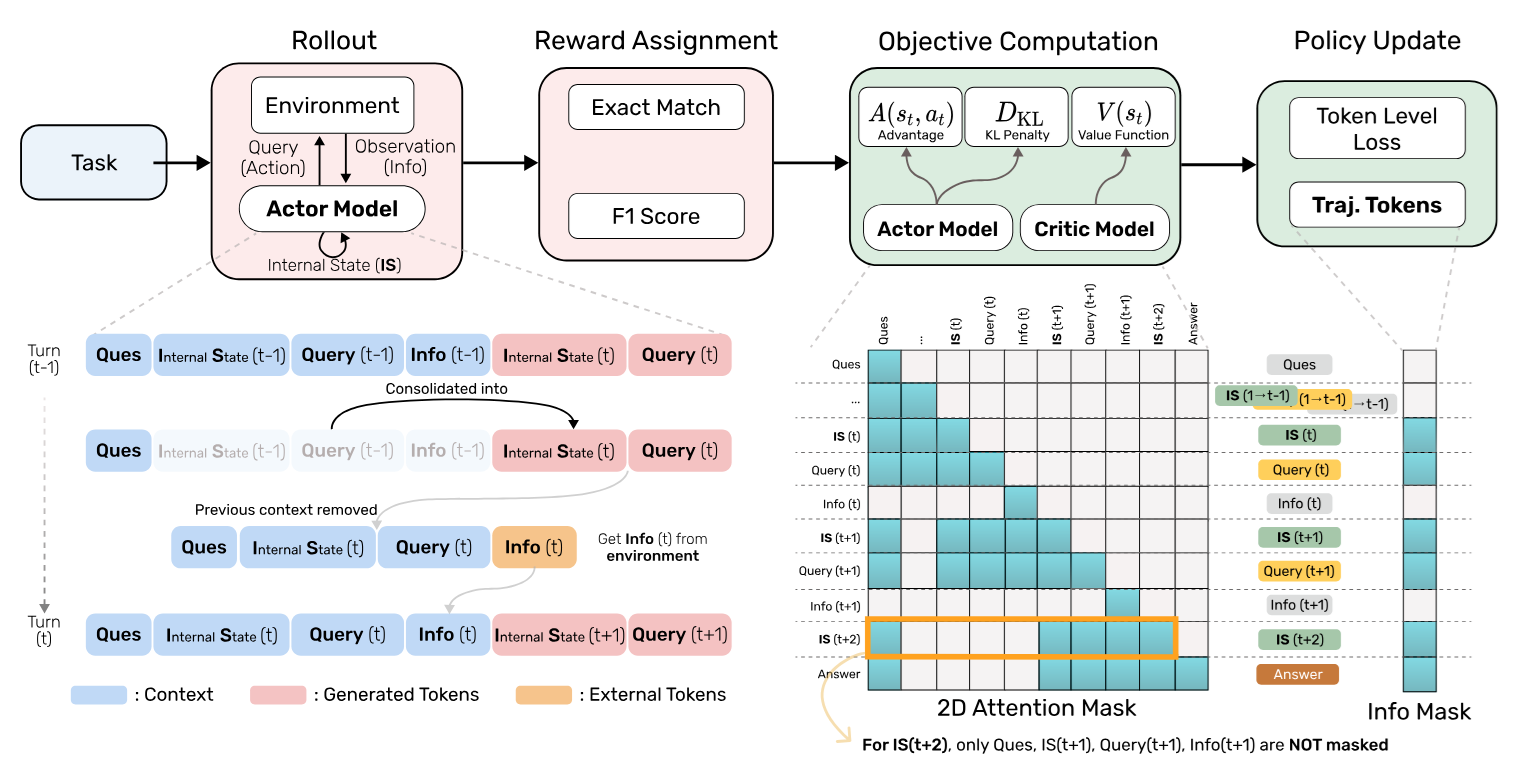
The authors consider an LLM that works in an agentic environment in the following way:
- Receiving a Question
- While the final answer isn’t obtained:
- Generating an Query (an action of sort towards the environment)
- Receiving an Info (which is a sequence of external tokens) from the environment
- Generating an Internal state (which is part memory, part planning)
- Retunring the Answer
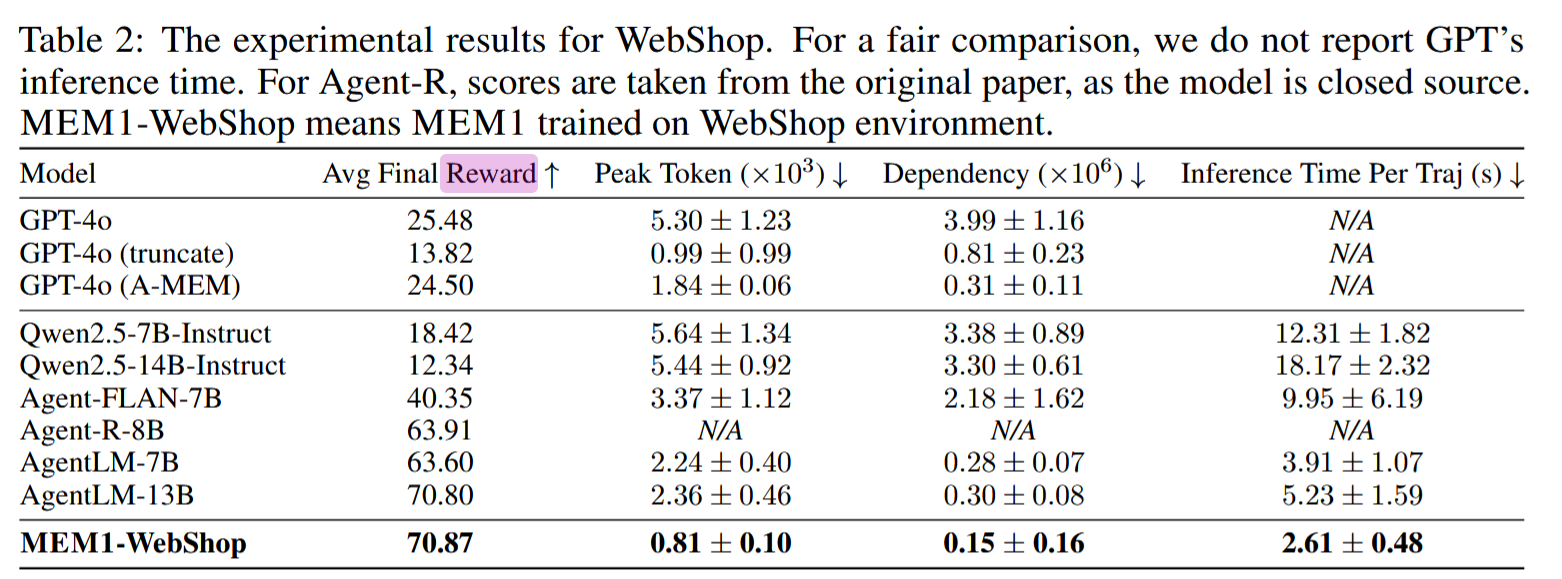
The model is trained with RL to achieve success on its agentic scenario - think of long-horizon web navigation in WebShop. Training data consists of model rollouts (agent’s trajectories).
Now, the crucial part is attention masking. The authors want to train the model to rely only on the last-to-date Internal state. So, during training (not during rollout), they impose the following attention mask, preventing the LLM from seeing the previous iterations:
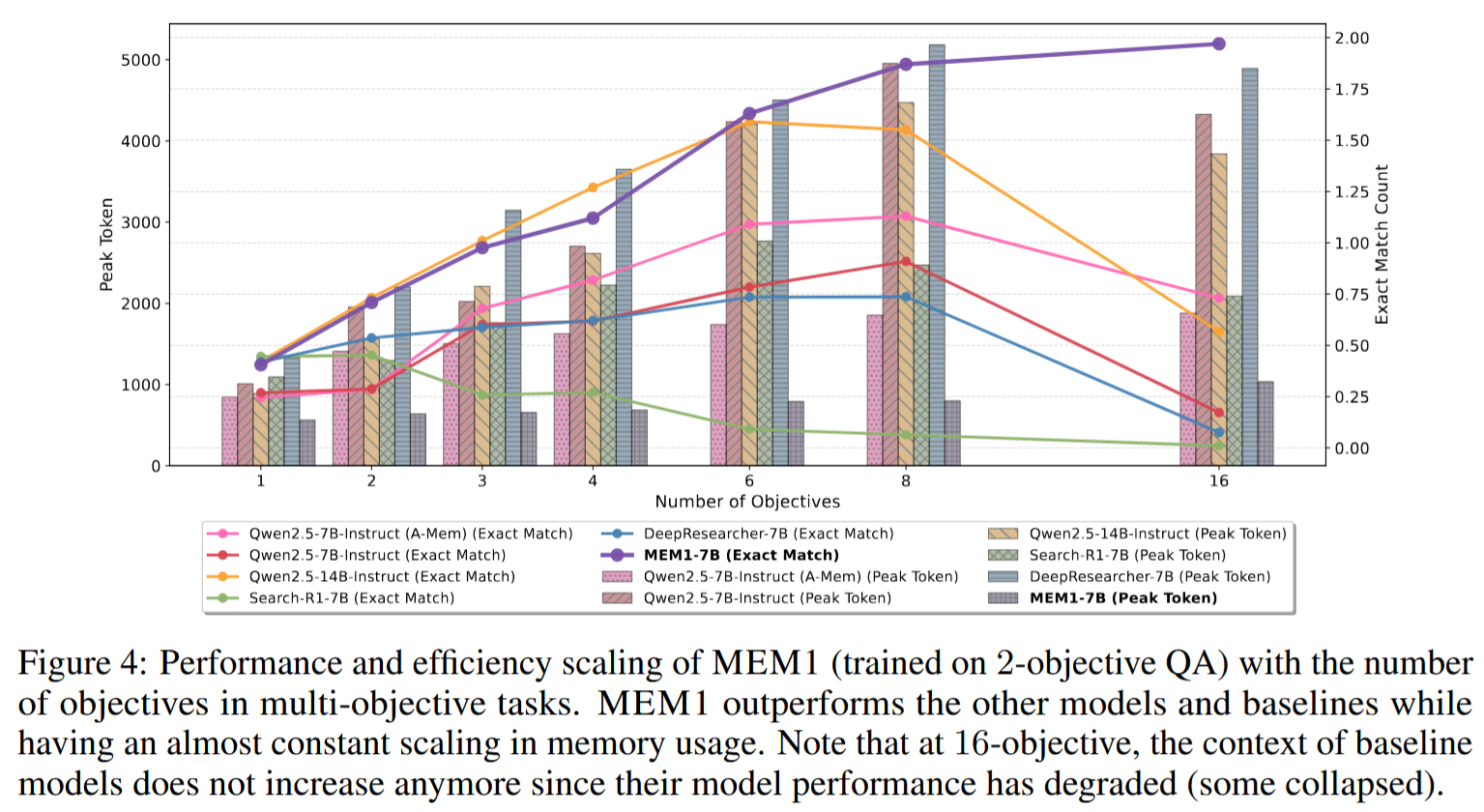
Here’s how the trained model (MEM1) works on a multi-hop QA task: its memory footprint stays bounded, while its performance doesn’t decrease with the number of goals.
The results of WebShop are also nice: