Text encoders are predominantly encoder-only transformers. We’ll brieftly discuss how they are trained, without going too deep into architectural details. If you need an embedding model for your project, check the Hugging Face embedding leaderboard to guide your decisions.
The purpose of encoder-only models is to produce meaningful embeddings, and there are two notable ways of achieving it. Both of them are self-supervised, that is allow to train model on synthetic supervised tasks, without external labeling.
Strategy 1: synthetic classification tasks
A famous example of this strategy is the BERT model, developed by Google. It was trained on two tasks:
- Masked Language Modeling: prediction of masked tokens,
- Next Sentence Prediction: checking whether two sentences could be together in a text.
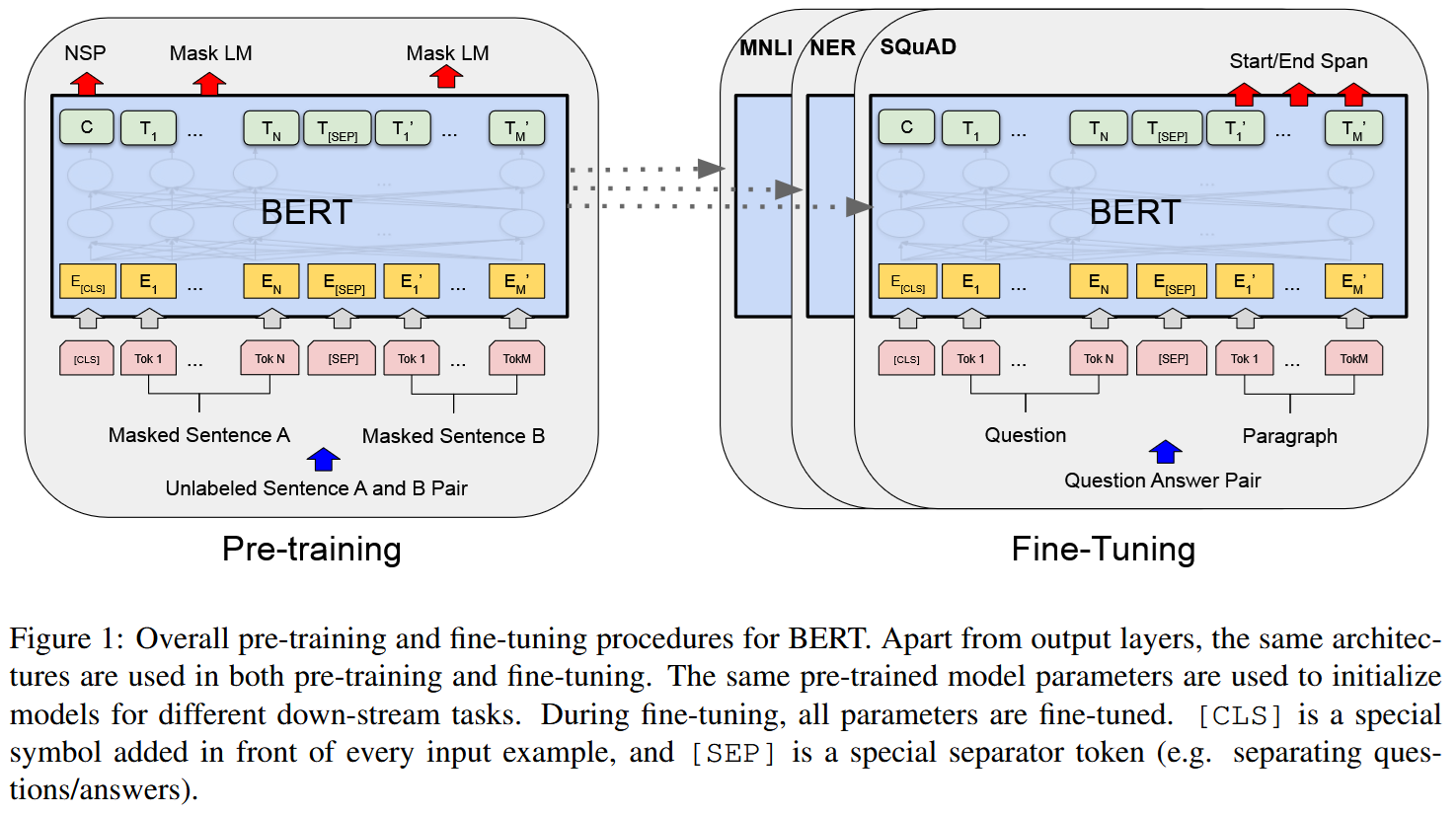
Further models were often trained for only Masked Language Modeling; on the other hand, Next Sentence Prediction forestalls the Strategy 2 we’ll discuss below.
BERT had many descendants; the most recent of them is ModernBERT published in December 2024, which adopted many architectural novelties used in recent LLMs such as
- Removal of bias terms in all linear layers except for the final unembedding layer,
- Fancy GeGLU activations,
- Rotary positional embeddings,
- Flash attention,
- Three-step training on larger and larger context length to achieve long-context (160K tokens) performance.
See the LLM architecture long read for more details about these features.
BERT-like models are mostly popular as bases for fine-tuning for classification, regression and similar tasks. However, they can also be used as encoders in vector stores.
Strategy 2: directly establishing coherence between semantic similarity and geometric proximity
While the central idea of BERT was to train a semantically rich embedding $E(x)$ for a text $x$, these models are trained with the following goal in mind: having two texts $x$ and $y$, the semantic relation between them should be well modeled by the number $s(x, y)$, which is a distance measure between $E(x)$ and $E(y)$, for example, a scalar product (the most popular option) or a Euclidean distance.
From the architectural point of view, there’s little difference between Strategy 1 and Strategy 2 models; their architecture often duplicates BERT or some of its descendants. But, as we’ll see, the training is different.
Contrastive training
Contrastive training operates with a dataset of tuples $(q, d^+, \mathcal{D}^-)$, where
- $q$ is the query.
- $d^+$ is the positive pair, that is a document which is relevant to the query. (Here “pair” refers to the fact that $q$ and $d^+$ are paired with each other.)
- $\mathcal{D}^- = {d^-_1,\ldots,d^-_n}$ are the negative pairs, that is documents which are irrelevant to the query.
The most popular loss function for contrastive training is the InfoNCE loss (introduced in this paper):
\[\mathcal{L} = -\log\frac{e^{s(q, d^+)/\tau}}{e^{s(q, d^+)/\tau} + \sum_{i=1}^ne^{s(q, d^-_i)/\tau} }\]where $\tau$ is the temperature parameter, and $s(q,d)$ estimates similarity between the embeddings of $q$ and $d$; for example, it can be cosine distance.
The trickier part is, however, where to get data with documents that can be paired as positive (relevant) and negative (irrelevant). Here are some potential sources:
- Search - for example, the classic MS MARCO dataset containing tuples (query, 10 passages with 1 relevant and 9 irrelevant), together with some more info.
- Knowledge-related Q&A,
- Fact verification datasets such as FEVER (Fact Extraction and VERification) containing claims generated by altering sentences extracted from Wikipedia together with labels Supported (by the original Wikipedia article), Refuted or NotEnoughInfo.
- Natural Language Inference (NLI) datasets such as SNLI containing sentence pairs labeled as contradiction, entailment (the logical consequence), or neutral. Like this:

Even though these datasets are reasonably large, they aren’t large enough for training of really powerful models, and this made popular the idea of two-stage training.
Two-step training
Partially inspired by LLM training procedures, his approach takes the idea of self-supervised learning to the new level. The two stages are:
-
Contrastive pre-training. Much like in LLM pre-training, this stage operates with huge and non-specific datasets: common web crawl, Wikipedia, stackoverflow etc. The notion of relevance is usually quite coarse. For example, two sentences may be deemed relevant to each other if they come for the same text (or paragraph). Irrelevant pair are often simply extracted from different entries of a training batch. This might seem naive, given how important choosing meaningful negative pair is for contrastive learning, but with a large batch size this approach works quite well.
-
Supervised Fine Tuning. This stage utilizes specialized datasets such as NLI and others discussed in the previous subsection, refining the model.
In SFT, datasets are smaller, and fining instructive and challenging negaive pair - mining hard negatives - becomes crucial. Hard negatives $d^-_i$ are negative pairs to a query $q$ that are negative (irrelevant) but semantically close to $q$. Using them instead of random in-batch negatives may greatly facilitate training.
To mine hard negatives, often an external reranker is used, scoring proximity of $d_i^-$ and $q$ for different in-batch negatives $d_i^-$.
Examples of models trained in this way are the GTE family (see this paper) and M3 Embeddings. Each of them have their own improvements over the base strategy, so feel free to check these papers!
LLMs as encoders
Though LLMs are decoder-only models, in contrast with the encoder-only BERT, we can still extract embeddings from them. For example, by taking the final representation of the end of string token:

Moreover, LLMs are already thoroughly pre-trained - if not for sentence relation prediction, then at least for general text understanding. And this allows to fine tune them for providing good embeddings with a quite modest dataset. It’s only left to subjeft the model’s final embedding to a specialized SFT with a contrastive loss.
The question is, of course, where to get the data for SFT, but even it may be generated by an LLM :) Like this:

Furthermore, In-Context Learning (that is, few-shot examples) may be used to steer the embedding generation and make it more flexible. Of course, you’ll need to fine tune the LLM to ensure that this mechanism provides good embeddings.
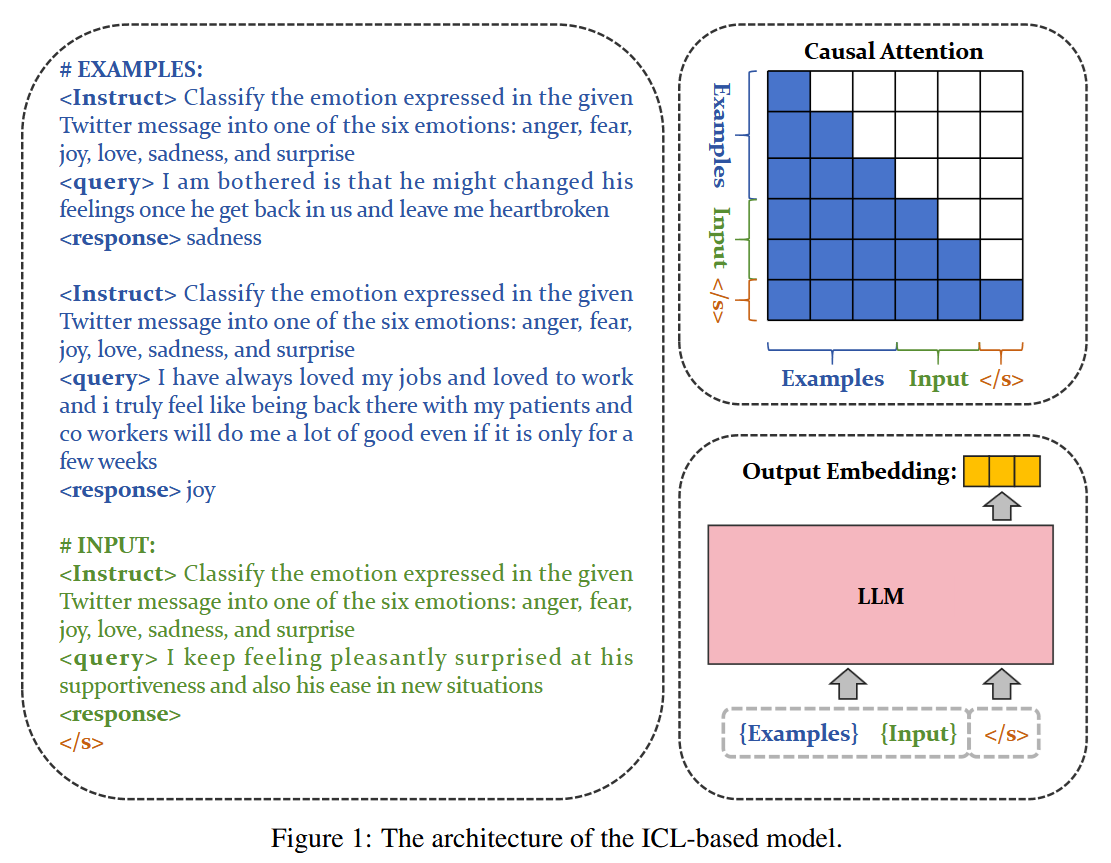
As GRIT demonstrates us, one can even train a model to work as both and LLM and an embedding provider:
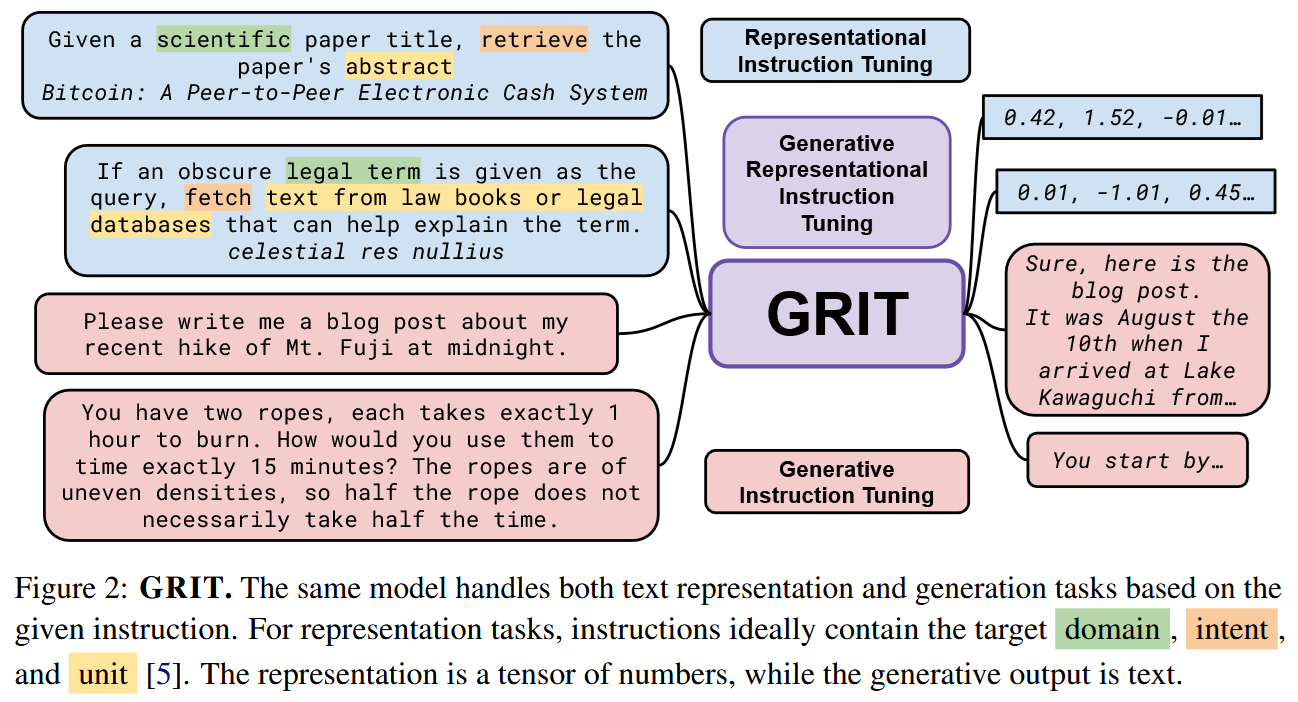
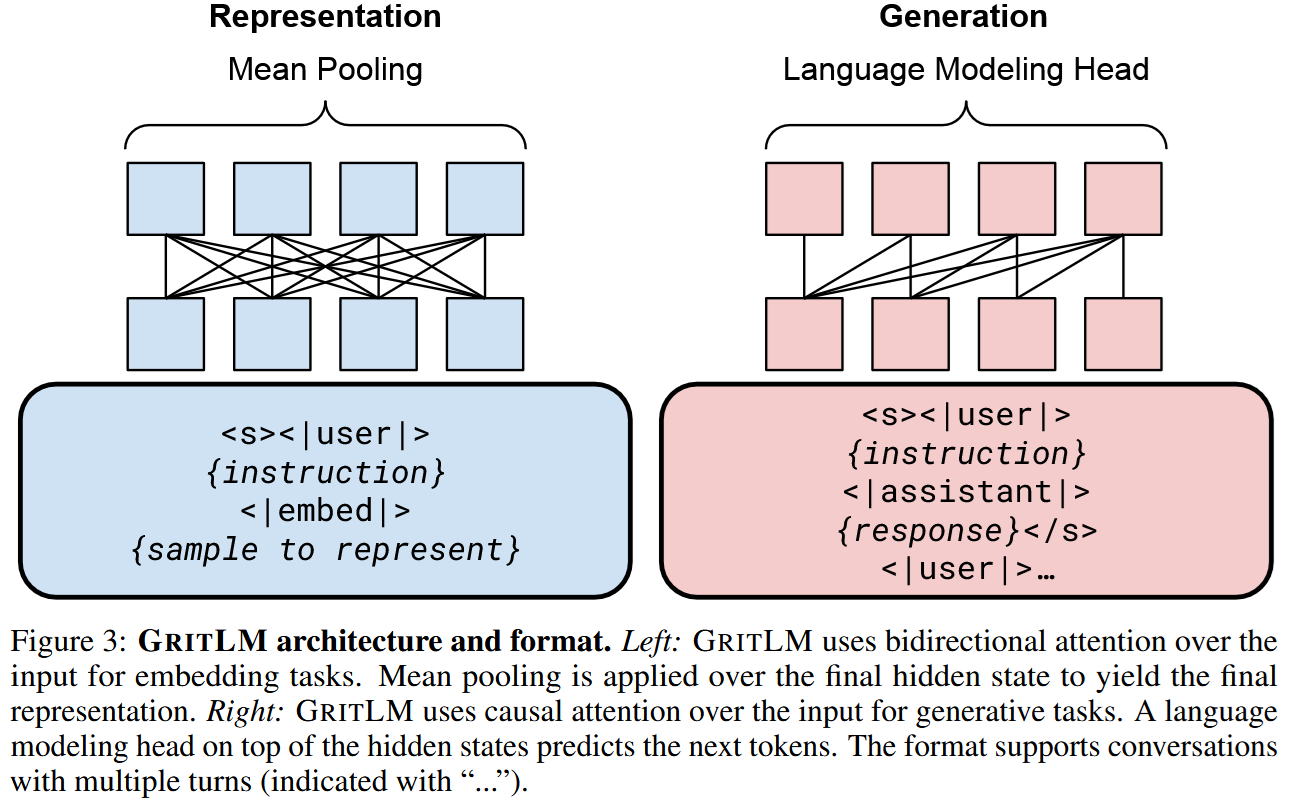
Of course, apart from different prompts, generation and embedding scenarios require
- Different attention pattern: bidirectional for the encoder scenario and causal (“never look into the future”) for the generation scenario
- Different output extraction: pooling of final embeddings for the encoder scenario and token prediction with LM head for the generation scenario
As for April 11, 2025, Nebius AI Studio serves several LLM-based encoders:
BAAI/bge-multilingual-gemma2andBAAI/bge-en-iclbased on the principles from Making Text Embeddings Few Shot Learnerse5-mistral-7b-instruct, see Improving Text Embeddings with Large Language Models for details